Introduction
ignition is a research microVM for macOS on Apple Silicon, built on Apple’s
Hypervisor.framework (HVF). It is architecturally modeled on AWS Firecracker, the
microVM model, the vstate seam, the device set, but it is not a port: it shares
roughly zero lines of Firecracker source. The lineage is the design plus the
rust-vmm building blocks Firecracker also uses. The one genuinely lifted piece is the
hvf crate, taken from libkrun and then
substantially reworked here.
The differentiator
The macOS microVM space is already contested by Virtualization.framework based tools,
so “isolated Linux microVM on a Mac” is not, by itself, a reason to exist. The
differentiator is the fast snapshot plus clone-from-warm-base primitive on bare HVF:
clonefile plus MAP_SHARED against an immutable base, where a clone idles at about
0% CPU and touches only its own dirtied pages. This is the Firecracker production
pattern. Virtualization.framework based tools cannot expose it cleanly, because they
sit on a closed whole-VM checkpoint API. ignition runs on raw HVF, so it can.
Positioning
ignition is a substrate that other tools are built on, not an end-user product. Its intended consumers are tool-builders: agent-sandbox authors, fuzzing harnesses, and CI backends, not Mac users at large. Everything is organized around making the clone primitive provably fast and correct, and reachable from infrastructure developers already run.
Two tracks
Two tracks carry the project beyond Firecracker parity:
- Demonstrator (snapshot fuzzing). The cleanest proof the clone primitive does real work: execs/sec is a direct function of reset latency, and a fuzz loop is the most brutal correctness test the snapshot path will ever face.
- Adoption (integration). Impersonate interfaces that already have consumers, MCP, the Firecracker REST API, and OCI, so adoption cost is near zero. One faithful seam at a time.
Where to go next
- Build & run, get a guest booting.
- The clone primitive, the core idea.
- How snapshot fuzzing works, the demonstrator.
- Roadmap, what is built and what is next.
Build & run
The runnable artifact is boot; it needs the hypervisor entitlement, which
relinking strips, so re-sign after every build.
cargo build
# the runnable artifact is `boot`; it needs the hypervisor entitlement before it
# can call hv_vm_create — re-sign after every build (relinking strips it):
cargo build -p ignition-spike --bin boot
scripts/sign.sh target/debug/boot
# usage (kernel + rootfs) is in "Boot a Linux guest" below.
Requirements
Apple Silicon Mac, macOS 15+ (26 preferred), Rust 1.96+ (edition 2024).
Boot a Linux guest
The boot binary loads an aarch64 kernel + rootfs, runs the vCPU(s), and gives
an interactive 16550 console. Re-sign after every build — relinking strips
the hypervisor entitlement.
cargo build -p ignition-spike --bin boot
scripts/sign.sh target/debug/boot
# boot to a shell (log in as root)
target/debug/boot kimage/out/Image kimage/out/rootfs.ext4
target/debug/boot --smp 4 kimage/out/Image kimage/out/rootfs.ext4 # multi-vCPU (SMP)
target/debug/boot --net kimage/out/Image kimage/out/rootfs.ext4 # vmnet NAT networking
Console keys: Ctrl-A s = snapshot, Ctrl-A x = quit, Ctrl-A b = balloon.
Snapshot and restore are covered in The clone primitive and Snapshot & restore.
Building guest assets
Agent playbook for rebuilding the aarch64 Firecracker guest kernel and rootfs in
kimage/. Both artifacts are built on the remote Linux host artemis2 (it
has Docker but no host toolchain — everything runs in containers) and pulled
back to kimage/out/. Full background lives in kimage/README.md; this file is
the operational checklist.
Mental model
- Sources you edit live locally in
kimage/build/:build-kernel.sh— cross-compiles Linux 6.1 aarch64 (ubuntu:22.04+gcc-aarch64-linux-gnu). Config = Firecracker CI config, fetched at build time, plusscripts/configtweaks, thenmake olddefconfig && make Image.build-rootfs.sh— provisionsalpine:3.19arm64, exports the fs, packs ext4 withmke2fs -d(no mount/sudo).devmem.c— static/dev/mempoke tool compiled into the rootfs.
- Artifacts land in
kimage/out/(gitignored):Image,rootfs.ext4. - The build runs in
~/kbuild/on artemis2. Kernel source/object tree is cached under~/kbuild/linux-6.1, so kernel rebuilds are incremental.
Workflow (every rebuild)
- Edit the script(s) locally under
kimage/build/. scpthe changed scripts toartemis2:~/kbuild/.- Run the build over
sshon artemis2. scpthe artifact(s) back tokimage/out/.- Verify magic bytes (below).
- Commit per the repo convention (plain message, no co-author trailer).
Rebuild the rootfs
cd kimage
scp build/build-rootfs.sh build/devmem.c artemis2:~/kbuild/
ssh artemis2 'cd ~/kbuild && chmod +x build-rootfs.sh && ./build-rootfs.sh'
scp artemis2:'~/kbuild/out/rootfs.ext4' out/rootfs.ext4
# verify ext4 magic 53ef at 0x438:
dd if=out/rootfs.ext4 bs=1 skip=$((0x438)) count=2 2>/dev/null | xxd
Rebuild the kernel
cd kimage
scp build/build-kernel.sh artemis2:~/kbuild/
ssh artemis2 'cd ~/kbuild && chmod +x build-kernel.sh && ./build-kernel.sh'
scp artemis2:'~/kbuild/out/Image' out/Image
# verify arm64 boot magic "ARMd" (4152 4d64) at 0x38:
xxd -s 56 -l 4 out/Image
For the GUI (virtio-gpu) milestone, the kernel config also needs CONFIG_DRM=y,
CONFIG_DRM_VIRTIO_GPU=y, CONFIG_DRM_FBDEV_EMULATION=y, CONFIG_FB=y, and
CONFIG_FRAMEBUFFER_CONSOLE=y so /dev/dri/card0 + /dev/fb0 appear and fbcon binds.
The GUI compositor (M4) also needs CONFIG_VIRTIO_INPUT=y and CONFIG_INPUT_EVDEV=y.
The browser rootfs additionally requires CONFIG_OVERLAY_FS=y and CONFIG_TMPFS=y.
These are needed only for the one-time warm-base cold boot (which passes
--append "ro init=/sbin/overlay-init" to set up the overlay root over a
read-only lower); restoring a
browser-base snapshot does not reload the kernel or re-run the overlay pivot.
Rebuild the GUI rootfs
A separate, larger rootfs (rootfs-gui.ext4) adds a cage (wlroots, pixman software
renderer) Wayland kiosk running foot, plus eudev/seatd/xkeyboard-config, for the --gui
window. It also carries the same netwatch carrier-poller as the base rootfs, so a
restored or cloned GUI guest rebinds virtio-net on restore and re-DHCPs with its fresh
MAC. Built by its own script so the minimal base rootfs stays untouched.
cd kimage
scp build/build-rootfs-gui.sh build/devmem.c artemis2:~/kbuild/
ssh artemis2 'cd ~/kbuild && chmod +x build-rootfs-gui.sh && ./build-rootfs-gui.sh'
scp artemis2:'~/kbuild/out/rootfs-gui.ext4' out/rootfs-gui.ext4
Run it: boot --gui --mem 512 out/Image out/rootfs-gui.ext4. The compositor takes the
framebuffer VT and foot renders fullscreen; type to drive the shell, move the pointer for
a software cursor. Without --gui (no /dev/dri/card0) the cage service no-ops and the
guest falls back to the serial console.
To snapshot and restore the live desktop, add --track-dirty, press Ctrl-A s to write
a snapshot, then boot --gui --restore <name> to reopen it. Fan out N clones from one
base with scripts/fanout-gui.sh N <name>. Add --net (under sudo) on both the
snapshot and the fan-out for networked clones — the GUI rootfs carries the netwatch
carrier-poller, so each clone rebinds virtio-net on restore and gets its own MAC + DHCP
lease. For in-memory reset without writing a new snapshot, Ctrl-A c marks the current
running desktop as a reset point and Ctrl-A r rolls it back in place (distinct from the
Ctrl-A s disk snapshot); this requires that the rootfs not diverge between checkpoint
and reset — mount it read-only with tmpfs for all writable state.
Rebuild the browser rootfs
A third rootfs (rootfs-browser.ext4) adds Firefox ESR in a kiosk configuration
plus /sbin/overlay-init, which the cold boot uses to mount the ext4 image
read-only as the lower overlay layer and a tmpfs as the upper layer before
handing off to init. The homepage URL is set at build time via HOMEPAGE; the
default is DuckDuckGo.
cd kimage
scp build/build-rootfs-browser.sh build/devmem.c artemis2:~/kbuild/
ssh artemis2 'cd ~/kbuild && chmod +x build-rootfs-browser.sh && HOMEPAGE=https://duckduckgo.com ./build-rootfs-browser.sh'
scp artemis2:'~/kbuild/out/rootfs-browser.ext4' out/rootfs-browser.ext4
See Disposable browser for warm-base creation and session management.
Rebuild the fuzz initramfs
The snapshot fuzzer (boot --fuzz) uses a separate minimal initramfs whose
/init is the static-musl harness in kimage/build/fuzz-harness/. Built the
same way (arm64 alpine container), packed as a newc cpio.
cd kimage
ssh artemis2 'mkdir -p ~/kbuild/fuzz-harness'
scp build/fuzz-harness/harness.c build/fuzz-harness/ignition_fuzz.h artemis2:~/kbuild/fuzz-harness/
scp build/build-fuzz-initramfs.sh artemis2:~/kbuild/
ssh artemis2 'cd ~/kbuild && chmod +x build-fuzz-initramfs.sh && ./build-fuzz-initramfs.sh'
# the script writes ~/kbuild/out/fuzz-initramfs.cpio, falling back to
# ~/kbuild/fuzz-initramfs.cpio if out/ is root-owned from a prior kernel build —
# pull from whichever exists:
scp artemis2:'~/kbuild/out/fuzz-initramfs.cpio' out/fuzz-initramfs.cpio 2>/dev/null \
|| scp artemis2:'~/kbuild/fuzz-initramfs.cpio' out/fuzz-initramfs.cpio
# verify newc cpio magic "070701" at byte 0:
head -c 6 out/fuzz-initramfs.cpio
The M2 build instruments target.c with -fsanitize-coverage=trace-pc and the
harness adds a third /dev/mem mapping for the coverage region at 0x09404000
(64 KiB); no new device nodes are needed (it reuses /dev/mem).
After editing harness.c (e.g. swapping the M0 stub target for a real one),
rebuild and re-pull. Keep ignition_fuzz.h in sync with
crates/devices/src/fuzz/protocol.rs.
libpng benchmark initramfs (M3)
The default ./build-fuzz-initramfs.sh (no arg → synthetic) keeps the ASan
chunk-parser with the planted overflow — that build owns the bug-finding number.
M3 adds a second target, libpng, that decodes real PNGs through libpng’s
simplified API (build/fuzz-harness/target_png.c).
The libpng target builds libpng 1.6.43 + zlib 1.3.1 from source with
-fsanitize-coverage=trace-pc only (no ASan). Rationale (spec §12): the
throughput / reset-latency / dirty-set numbers must isolate the snapshot machinery
from ASan’s shadow-memory churn, so the coverage-only build strips ASan while
keeping edge coverage. Crashes (if any) surface via the harness signal handlers
rather than ASan. The synthetic ASan build stays the default and unchanged.
Build notes (encoded in the script):
configure’s “can the compiler link an executable?” probe compiles a trivialmainwith$CFLAGS; withtrace-pcthat emits an unresolved__sanitizer_cov_trace_pc(the callback lives inharness.c, which configure never sees), so the probe is handed a no-op definition viaLDFLAGS(/build/covstub.o). It never enterslibz.a/libpng16.a, so the shipped library code stays fully instrumented.harness.cis shared with the synthetic build and references__asan_set_death_callback; the no-ASan link supplies a no-op/build/asanstub.ofor it (never called here).harness.cis unchanged.- zlib is fetched from the GitHub release tarball
(
github.com/madler/zlib/releases/...);zlib.net/zlib-<ver>.tar.gz404s for non-current versions.
Rebuild + pull fuzz-initramfs-libpng.cpio (distinct output name, coexists with
the synthetic cpio in out/):
cd kimage
ssh artemis2 'mkdir -p ~/kbuild/fuzz-harness'
scp build/fuzz-harness/harness.c build/fuzz-harness/ignition_fuzz.h build/fuzz-harness/target_png.c artemis2:~/kbuild/fuzz-harness/
scp build/build-fuzz-initramfs.sh artemis2:~/kbuild/
ssh artemis2 'cd ~/kbuild && chmod +x build-fuzz-initramfs.sh && ./build-fuzz-initramfs.sh libpng'
scp artemis2:'~/kbuild/out/fuzz-initramfs-libpng.cpio' out/fuzz-initramfs-libpng.cpio 2>/dev/null \
|| scp artemis2:'~/kbuild/fuzz-initramfs-libpng.cpio' out/fuzz-initramfs-libpng.cpio
head -c 6 out/fuzz-initramfs-libpng.cpio # expect 070701
The remote build log should end with ldd /out/root/init showing only
ld-musl-aarch64.so.1 (libpng + zlib are static).
Verify (must pass before committing)
| Artifact | Check | Expect |
|---|---|---|
out/Image | xxd -s 56 -l 4 out/Image | 4152 4d64 (ARMd) |
out/rootfs.ext4 | dd ... skip=$((0x438)) count=2 | xxd | 53ef |
Hard rules
- Never
strip/objcopythe arm64Image. It is a valid PE/COFF binary; strip rewrites it and destroys the boot magic at0x38. Copy verbatim. Symptom of corruption: header4d5a 9000 ...and zeros at0x38. - Pull artifacts back after the build — local
out/keeps the old build until youscp. A staleout/Imagedate means the re-pull didn’t run. out/is gitignored (large reproducible binaries) — artifacts are not committed, only the build scripts are.- One-time host prereq on a fresh Docker host: register arm64 binfmt —
docker run --privileged --rm tonistiigi/binfmt --install arm64.
Common edits
- Kernel config: add
--enable/--disablelines to thescripts/configblock inbuild-kernel.sh(beforeolddefconfig). The script echoes the requested CONFIG lines afterolddefconfigso you can confirm they survived. - Rootfs packages: add
apk addlines in the alpine provisioning block ofbuild-rootfs.sh; bump the96Mmke2fssize if it grows. - Kernel version: change
KVERand the config URL inbuild-kernel.sh(Firecracker ships 5.10 and 6.1 aarch64 configs).
See kimage/README.md for the artifact table, boot config JSON, SMP/PSCI
requirements, and the extra kernel features (virtio-balloon, vsock, devmem).
Architecture
ignition is a research microVM for macOS on Apple Silicon, built on Apple’s
Hypervisor.framework (HVF). It is architecturally modeled on AWS Firecracker (the
microVM model, the vstate seam, the device set) but it is not a port: it shares
roughly zero lines of Firecracker source. The lineage is the design plus the
rust-vmm building blocks Firecracker also uses (vm-superio, vm-fdt). The one
genuinely lifted piece is the HVF backend, taken from libkrun and then
substantially reworked.
Crates
The workspace splits cleanly along the seam between architecture-neutral VMM logic and the macOS/HVF hypervisor backend.
crates/
arch/ ignition-arch aarch64 sysreg tables, boot regs, FDT helpers
hvf/ ignition-hvf Hypervisor.framework backend (lifted from libkrun, reworked)
devices/ ignition-devices serial / virtio / GIC device implementations
vmm/ ignition-vmm the vstate seam: HVF replacement for FC kvm/vm/vcpu
spike/ ignition-spike the `boot` binary (interactive microVM)
Crate library names are ignition_*. Because the hvf crate was lifted from
libkrun and then reworked (direct hv_gic_*, SMP, snapshot/restore), its imports
were updated to match the ignition tree.
The vstate seam
Firecracker isolates everything KVM-specific behind a small set of files:
vstate/{kvm,vm,vcpu,memory,interrupts}.rs plus the MMIO device manager. That is
the surface a VMM has to replace to move off KVM. ignition cuts at the same seam
and substitutes HVF for KVM there:
KVM_CREATE_VMbecomeshv_vm_create;KVM_SET_USER_MEMORY_REGIONbecomeshv_vm_map. There is one VM per process on HVF.KVM_CREATE_VCPUbecomeshv_vcpu_create, which on HVF must run on the thread that will execute the vCPU (the vCPU is thread-affine). This inverts Firecracker’s create-then-move model: ignition spawns the thread first and creates the vCPU inside it.- The in-kernel GIC is created with
hv_gic_createinstead ofKVM_CREATE_DEVICE, and its state is captured losslessly throughhv_gic_state_*. - Interrupt injection has no irqfd. A device interrupt is a synchronous
hv_gic_set_spi(line, level)call plus a wake of any parked vCPU. There is also noKVM_IOEVENTFD, so every virtio kick is a full exit to userspace.
ignition-vmm owns this seam; ignition-hvf provides the raw HVF wrappers it
drives.
The run loop
KVM_RUN returns a typed exit. HVF returns a raw hv_vcpu_exit_t (a reason plus
the ESR_EL2 syndrome), so ignition decodes the exception itself. The run loop
reads the exit reason (CANCELED, EXCEPTION, VTIMER_ACTIVATED) and, for an
exception, the EC field (syndrome >> 26) & 0x3f, then dispatches:
- MMIO (Data Abort, EC
0x24): decode the ISS (access size, source register, read/write) and the faulting guest physical address. HVF cannot complete a read inside the handler, so ignition stashes the pending read and completes the register writeback plus the PC advance on the next run loop entry. - System-register trap (EC
0x18): decode the packed sysreg id and dispatch to a read/write handler. With the in-kernel GIC this class nearly disappears. - WFI/WFE idle (EC
0x1): this is the idle loop, in userspace. If the virtual timer is disabled or masked the vCPU parks indefinitely; otherwise it parks with a timeout derived fromCNTV_CVAL_EL0againstmach_absolute_time(). A device IRQ wakes the parked vCPU over a per-vCPU channel. - PSCI (HVC
0x16/ SMC0x17): ignition is the PSCI firmware. It implementsPSCI_VERSION,SYSTEM_OFF/SYSTEM_RESET, andCPU_ON(the SMP path that hands an entry point to a parked secondary vCPU thread). SMC needs a manual PC advance; HVC does not.
For the source-level mapping of every KVM construct to its HVF replacement, see HVF and Firecracker map.
Related
- Device model — how devices plug into this architecture.
- The clone primitive — the snapshot/restore feature built on it.
Device model
ignition wires every device through one uniform path. A DeviceManager owns the
set of devices, and each device implements the MmioDevice trait. That single
abstraction handles MMIO-window and SPI allocation, bus dispatch, FDT node
emission, and snapshot enumeration, so adding a device does not mean touching the
boot path, the FDT generator, and the snapshot writer separately.
DeviceManager and the MmioDevice trait
DeviceManager centralizes what would otherwise be scattered per-device
plumbing:
- MMIO / SPI allocation. The manager hands each device a slice of the MMIO address window and an SPI line, so device placement is decided in one place instead of being hard-coded per device.
- Bus dispatch. A guest MMIO access (decoded from a Data Abort in the run loop) is routed to the device whose window contains the faulting address.
- FDT node emission. Each device describes its own FDT node (
reg, interrupt, compatible string). The FDT generator walks the manager rather than hard-listing devices, so the device tree the guest sees always matches the devices that are actually wired. - Snapshot hooks. Each device emits a
DeviceRecordat snapshot time and is reconstructed from one at restore. The snapshot format is a self-describing list of these records rather than a hand-maintained struct of device fields.
Because the same DeviceManager describes devices for both a fresh boot and a
restore, there is a single device-wiring site. Boot and restore drive the same
code to allocate windows, register on the bus, and produce or consume device
records, which keeps the two paths from drifting apart.
The shipped device set
ignition implements the full Firecracker aarch64 device set:
- virtio-blk for the root filesystem.
- virtio-net over a vmnet NAT backend.
- virtio-rng backed by host entropy.
- virtio-balloon for on-demand memory reclaim.
- virtio-vsock for guest-to-host streams.
- PL031 RTC for wall-clock time.
- boot-timer, a magic-MMIO probe that reports guest boot time (and that the fuzzer reuses as a control-plane doorbell).
For the per-device behavior, the networking model, and the SMP wiring, see Devices, SMP & networking.
Related
- Architecture — where the device manager sits in the VMM.
- The clone primitive — how
DeviceRecordsnapshot hooks are used. - VM internal API (MMIO) — the guest-facing MMIO contract (boot-timer, fuzz device).
The clone primitive
The reason ignition exists is the fast snapshot and clone-from-warm-base primitive on bare HVF: an immutable base, lazy copy-on-write clones that idle near 0% CPU and touch only their own dirtied pages, and a microsecond-budget in-loop reset. This chapter walks the primitive from the bottom up, in the order the pieces were built.
1. Snapshot and restore
A running guest can be snapshotted and later restored into a fresh guest that resumes from the saved PC, keeps time, accepts console input, and idles at roughly 0% CPU at its WFI. Restore loads RAM, creates the GIC and vCPUs, restores the GIC state, applies the saved register, timer, and device state, and resumes. There is no kernel reload and no FDT regeneration.
The on-disk format is self-describing (v2, magic ignition-snapshot-v2): a list
of DeviceRecord entries rather than a hand-listed set of device fields, guarded
by a version check that rejects older snapshots. With more than one vCPU, snapshot
is a stop-the-world rendezvous: every online core saves itself and, on restore,
resumes at its own PC.
2. Fast restore
Restore does not copy RAM. It uses clonefile to make a copy-on-write clone of the
base memory.bin, then maps it with mmap(MAP_SHARED). Pages fault in lazily as
the guest touches them, and the immutable base is never mutated. macOS has no
userfaultfd, so this is the macOS analogue of Firecracker’s MAP_PRIVATE/UFFD
restore: clonefile plus MAP_SHARED already demand-pages host-side.
3. Snapshot store
The store lays clones out so the base stays immutable and every instance is isolated:
snapshots/<name>/ immutable bases (memory.bin, gic.bin, vmstate.json, disk.img)
instances/<name>-<pid>/ per-instance CoW clones of the base
manifest.json named lineage and metadata
A snapshot writes a base under snapshots/<name>/; each restore clones it into its
own instances/<name>-<pid>/ directory. Two restores of the same base yield two
fully independent guests.
4. Dirty tracking on HVF
HVF has no KVM_GET_DIRTY_LOG and no exposed hardware stage-2 dirty bit, so dirty
tracking is the genuinely novel platform bit. ignition arms it with
hv_vm_protect: it drops HV_MEMORY_WRITE on the guest RAM pages, so the first
write to each clean page traps. The trap arrives as a Data Abort (EC 0x24) whose
faulting IPA is exactly the dirtied page; ignition marks the page dirty, re-grants
write permission, and resumes without advancing the PC so the store
re-executes.
Two hardware facts shaped this. The protect granule is 16 KiB (the Apple Silicon
host page); a 4 KiB sub-range is rejected with HV_BAD_ARGUMENT, so the dirty
bitmap is one bit per 16 KiB page. And HVF reports these as translation faults
(DFSC 0x07/0x0f), not permission faults, so the dirty path keys off “write data
abort whose faulting address lands inside the RAM region” rather than a specific
DFSC sub-code. Measured cost is roughly 4.9 µs per first-write fault, one vmexit
per first write to each page per interval.
5. Diff / incremental snapshots
With dirty tracking armed, a restored guest can write a Diff layer that contains
only the pages it changed, with its parent set to the leaf it restored from. The
result is an immutable delta chain rather than a base file that mutates in place.
Restore reassembles the guest transparently by layering the root base plus each
diff in order.
6. In-loop reset()
The fuzzer needs to roll a live guest back to a known state on every iteration,
inside the running VMM, with a microsecond budget. The in-loop reset() does this
entirely in memory: it copies back only the dirtied pages and restores the vCPU
registers, with no disk, no format, and no versioning. It reuses the dirty-tracking
substrate, so the work per reset is proportional to the dirty set, not to total
RAM. Measured reset p50 is about 36 µs (page-copy roughly 35 µs plus register
restore roughly 1 µs).
See also
Snapshot & restore
See The clone primitive for the mechanism.
ignition snapshots a running guest and restores it lazily from an immutable base.
Update (2026-06-13): device wiring now goes through a uniform
DeviceManager(vmm::device_manager) — MMIO-window/SPI allocation, bus registration, FDT-node description, and snapshot enumeration are centralized behind theMmioDevicetrait. The snapshot format is v2 (SNAP_MAGIC = "ignition-snapshot-v2"): a self-describing device-record list replaces the hand-listedVmConfigdevice fields, with acheck_versionguard rejecting older snapshots. Live snapshot/restore/clone re-verified green after the refactor.
What works, end to end
- Snapshot (
Ctrl-A s): writes a complete directory —memory.bin(RAM dump),gic.bin(thehv_gic_statedistributor/redistributor blob),disk.img(rootfs copy),vmstate.json(vCPU + device state). The guest resumes after snapshotting. - Restore (
boot --restore <dir>): loads RAM, creates the GIC + vCPU, restores the GIC state, applies the saved register/timer/device state, and resumes from the saved PC — no kernel reload, no FDT regeneration. - Responsive + idle: the restored guest parks at ~0% CPU at its idle WFI and responds to typed input (login prompt, shell commands).
- Clone: restoring one snapshot twice yields two independent guests (private
per-clone disk copy under
std::env::temp_dir()).
Drivers (live, not cargo test — they need the hypervisor entitlement + a real
kernel/rootfs): scripts/restore_test.py (snapshot → restore → CPU% + responsive),
scripts/restore_clone_test.py (login + command + two clones).
Bugs found and fixed via live restore debugging
Each was confirmed by the guest’s failure mode changing:
- GIC restore needs create-first.
hv_gic_set_staterestores INTO an existing in-kernel GIC; it does not create one. Create the GIC (hv_gic_create, same placement as a fresh boot) before restoring its state. - Pointer-authentication keys. The restored guest faulted on
autiasp(“Attempted to kill the idle task”). The kernel signs return addresses with the PAC keys (APIA/APIB/APDA/APDB/APGA, HI+LO); a restored vCPU needs the same keys. Added all 10 to the captured set. - FP/SIMD state. Added Q0–Q31 + FPCR/FPSR capture/restore (otherwise glibc’s NEON paths corrupt on resume).
- The livelock — three interacting causes (see below).
The livelock: root cause and the three-part fix
After (1)–(3) the restored guest no longer crashed but livelocked at 100% CPU,
PC pinned at the idle wfi (arch_cpu_idle / cpu_do_idle), with zero host
exits — i.e. spinning entirely inside hv_vcpu_run. Systematic instrumentation
(a kicked PC + vtimer-state sampler) established:
- The vtimer fires once;
CNTV_CTL.ISTATUSlatches andCNTV_CVALthen never moves — the guest never re-arms it, so the timer IRQ is never serviced. - WFI wakes on the pending vtimer (so it never traps to the host → no exit), but the
IRQ is never delivered as an exception (PC never enters a handler). Forcing
PSTATE.Iclear did not help → the interrupt was not deliverable at the CPU interface at all.
Three things had to be true for the guest to resume correctly:
- GIC state must be restored AFTER the vCPU exists.
hv_gic_set_staterestores the per-cpu redistributor state, which includes the PPI enable bits that gate the virtual-timer interrupt (PPI 27). Restoring it before the vCPU is created (the old code created the GIC and restored its state up front, then created the vCPU) silently dropped the redistributor state, so the timer IRQ was never delivered. This was the actual livelock. Fix:HvfGicV3::newcreates the GIC up front;gic_restore(blob)applies the saved state on the vCPU thread, afterHvfVcpu::new, beforerestore_state. (crates/hvf/src/gic.rs,crates/vmm/src/vstate/vcpu_manager.rs::run_restored_primary.) - The WFI exit handler must be vtimer-offset-aware (
crates/hvf/src/lib.rs,EC_WFX_TRAP). It comparedCNTV_CVALagainst rawmach_absolute_time(). That is correct only whenvtimer_offset == 0(fresh boot). With a nonzero restore offset it read the comparator as perpetually expired and the host busy-looped onWaitForEventExpired. Fixed to compare againstCNTVCT = mach - vtimer_offset(read back viahv_vcpu_get_vtimer_offset); reduces to the original on a fresh boot. - The vtimer offset must make CNTVCT continuous across the snapshot
(
restore_state). At snapshot timevtimer_offset == 0, soCNTVCT == CNTPCT == mach_absolute_time() == host_counter(captured). On restore, setoffset = mach_now - host_counterso CNTVCT resumes at the captured value instead of jumping forward by the wall-clock gap (a forward jump expires every armed clock-event deadline at once → timer storm).
On Apple Silicon CNTPCT == mach_absolute_time() and CNTVCT = CNTPCT - offset;
these were confirmed empirically by the offset/cval/cntvct sampler.
Tests / gate
15 test suites green (serde round-trips for every state struct; device save/restore; snapshot dir write/read/magic). Workspace builds, 0 clippy. Live snapshot→restore and clone verified by the two driver scripts above.
GUI snapshot, restore & fan-out
A --gui guest (the cage + foot desktop over virtio-gpu/virtio-input) snapshots
and restores like any other: Ctrl-A s writes a snapshot of the live desktop,
and boot --gui --restore <name> reopens a window with the desktop resuming
where it left off. The virtio-gpu resource table and scanout binding plus the
virtio-input config cursor are serialized; pixels are not — on restore the
device re-reads the scanout from the restored guest-RAM backing and presents one
frame, so the window paints the resumed screen before the guest runs again.
Because each restore clones the immutable base into its own copy-on-write instance dir (keyed by pid), one warm base fans out into N independent desktops, each with its own window:
# take one warm-base snapshot of a logged-in desktop (Ctrl-A s), then:
scripts/fanout-gui.sh 3 warm-base
# -> 3 boot --gui --restore processes, 3 windows, 3 isolated guests
Networking fans out too. Pass --net (needs sudo for vmnet shared mode) when
you snapshot and when you fan out, and each clone gets its own MAC and DHCP
lease — verified with 3 simultaneous clones, each on a distinct IP:
sudo scripts/fanout-gui.sh 3 warm-base --net
This works because the GUI rootfs runs the same netwatch carrier-poller as the
base rootfs: every restore starts a fresh vmnet interface (new MAC) and the VMM
bounces the virtio-net link down→up, the poller catches that edge, rebinds
virtio_net so the guest re-reads the fresh MAC, then re-runs DHCP. Without the
poller a restored guest would keep the snapshot’s MAC and every clone would DHCP
to the same address.
The base snapshot is never mutated; closing a clone’s window tears down only that guest.
Interactive reset-to-checkpoint
Two console hotkeys let you capture a running guest’s state as an in-memory “reset point” and roll the live guest back to it without tearing the VM down:
Ctrl-A c— mark the current moment as the reset point. The VMM captures guest RAM (via an O(1) APFSclonefilecopy), vCPU registers, GIC state, and virtio-device state, then prints[reset point marked]and lets the guest continue.Ctrl-A r— roll the running guest back IN PLACE to that reset point: guest RAM is restored (only the pages that changed when--track-dirtyis armed, or a full copy without it — both produce a correct result), vCPU registers, GIC state, and virtio-device state are all applied, and under--guithe rolled-back screen is repainted. The guest then resumes from the reset-point moment. Prints[reset to checkpoint]. If no reset point exists yet, printsreset: no checkpoint - press Ctrl-A c first.
The in-place reset above is the serial/headless path. Under --gui it is not
used: Ctrl+Alt+R instead does a cold reset — the process exits with a
sentinel code and the launcher re---restores the clone (a fresh window at the warm
state). An in-place rollback of a live, actively-rendering GUI cannot reconcile the
running GIC + virtio-gpu/net state with the rolled-back guest (hv_gic_set_state is
create-time-only on HVF, so in-flight interrupt state wedges the display under load),
whereas a fresh --restore builds clean devices and the guest re-initialises.
Ctrl+Alt+S (disk snapshot) and Ctrl+Alt+X (close) are the other window
hotkeys; the serial console keeps the full Ctrl-A set.
Device (DMA) writes are now tracked. The dirty tracker covers both vCPU-fault writes
and device-side writes to guest RAM (virtio used-ring updates, RX frame data, block-read
data, etc.). A DirtySink hook at the device-facing GuestRam write path marks the same
write-protect bitmap as the page-fault handler, so the two paths share a single consistent
dirty set. As a result, Ctrl-A r is once again a fast dirty-only rollback — only the
pages that actually changed since the checkpoint are copied back, regardless of whether
they were written by a vCPU or a device. Without --track-dirty the reset falls back to
a full RAM copy as before. Diff snapshots (Ctrl-A s with --track-dirty) also benefit:
device-written pages are no longer omitted from the delta, so incremental snapshots are
correct even when the guest was doing active DMA between the base and the diff.
Auto-seed on --restore. When a guest is started with `boot –restore
Distinct from Ctrl-A s. Ctrl-A s writes a named snapshot directory to
disk (a full, persistent snapshot usable for future restores and fan-out clones).
Ctrl-A c/Ctrl-A r operate entirely in memory and on the live guest; no
directory is written.
GIC mid-run re-restore. Applying GIC state to a running guest (hv_gic_set_state
while the VM is live) is best-effort: all vCPUs are parked before the call and
the state is applied atomically from their perspective. If HVF rejects the call
mid-run the reset logs [reset] gic_restore rejected mid-run ... and continues;
any in-flight interrupts re-settle within a tick or two. This is the designed
fallback — the guest remains functional.
Disk non-divergence is required for correctness. Reset rolls back guest RAM, vCPU registers, GIC state, and virtio-device state, but the disk is NOT rewound. If the guest has written to a read-write rootfs between the checkpoint and the reset, the rolled-back guest RAM (page cache, ext4 journal, inode cache) will describe a disk that has moved on, causing filesystem corruption.
The intended usage mounts the rootfs read-only and places all writable state (
/tmp, browser profile, downloads, etc.) on a tmpfs overlay that lives in guest RAM. That RAM rolls back cleanly withCtrl-A r, and the immutable rootfs never diverges. A read-write rootfs that is written betweenCtrl-A candCtrl-A rwill corrupt the filesystem.
Related
- The clone primitive — the mechanism behind this feature.
- Diff / incremental snapshots — only-changed-pages snapshots on top.
- Boot & restore latency — how fast restore is.
Diff / incremental snapshots
A diff snapshot writes only the guest RAM pages that changed since the base, instead of dumping all of RAM every time.
Arming dirty tracking with --track-dirty
--track-dirty arms write-protect dirty tracking. Guest RAM is mapped read-only and
the first write to each 16 KiB page traps as a data abort, faults the page back to
writable through hv_vm_protect, and marks it dirty. The faulting guest IPA is exactly
the page address the tracker needs, so the store re-executes after the page is granted
write access (the PC does not advance). 16 KiB is the tracking granule because it
matches the Apple Silicon host page; hv_vm_protect rejects sub-page ranges. HVF has
no native dirty-bitmap API, so write-protect plus data-abort interception is the only
precise dirty mechanism on the platform.
The delta-chain model
A restored guest armed this way writes a Diff layer on Ctrl-A s. The layer records:
parent= the leaf it was restored from.- Only the changed RAM pages (RAM is the only deltified state).
- vmstate, the GIC blob, and device records, always written full per layer.
Layers form an immutable delta chain rooted at a full base. The runtime cost is one
vmexit per first write to each clean page (about 5 microseconds per fault, measured),
amortized because each page faults at most once per interval. Snapshotting under the
same name as the parent, or the base it was restored from, is refused without
--force.
Restore reassembly
Restore reassembles the chain transparently: clonefile the root base, then overlay
each diff’s pages in order. Because the base is cloned with copy-on-write and the
deltas are layered at restore time, the chain stays immutable at rest.
Example
# boot armed for diff tracking, snapshot a root, then restore + diff-snapshot
target/debug/boot --store vmstore --name base --track-dirty kimage/out/Image kimage/out/rootfs.ext4
target/debug/boot --store vmstore --restore base --track-dirty --name base-diff
# full cycle: diff ~3% of RAM, mutation survives, bases immutable
python3 scripts/diff_snapshot_test.py
Worked example of one warm golden base fanning out into many cheap divergent forks: diff-snapshot-fanout.md.
Related
- The clone primitive — dirty tracking and the delta chain.
- Snapshot & restore — the full snapshot this builds on.
- Diff-snapshot benchmarks — tracking overhead and sizes.
Devices, SMP & networking
ignition wires its devices through a uniform DeviceManager: MMIO-window and SPI
allocation, bus registration, FDT-node description, and snapshot enumeration all sit
behind the MmioDevice trait.
Console
A 16550 UART provides a fully bidirectional console. TX drains to stdout; RX buffers
typed input into the UART’s RX FIFO, sets the LSR data-ready bit, and raises the RX
interrupt over the same GIC serial line (INTID 32) that TX uses. A reader thread runs
an escape FSM (Ctrl-A x quits) and forwards bytes into the device, so a real
interactive root login works: type root, get a shell, run commands, detach with
Ctrl-A x.
virtio devices
virtio runs over a generalized virtio-mmio transport: a VirtioDevice trait
(device_id/device_features/config_read/queue_count/handle_notify/inject_rx)
with per-queue state, hardened feature-select clamping, and a QueueReady invariant.
Config space (offset >= 0x100) is byte-addressable at any access width, which Linux
needs because it reads multi-byte config fields one byte at a time.
- virtio-blk carries the real rootfs over a split virtqueue. The device probes, the guest mounts ext4 over the virtqueue, and init runs off the disk. A boot serviced roughly 692 virtqueue requests (about 605 reads, 62 writes) through the QueueNotify -> walk -> file I/O -> used-ring -> SPI path.
- virtio-rng, virtio-balloon, and virtio-vsock round out the block-era device set.
virtio-net + vmnet
--net (opt-in) brings up a virtio-net NIC backed by vmnet.framework in shared/NAT
mode through a C shim. The full data path (TX -> vmnet -> RX -> IRQ on INTID 34 ->
guest) is proven on hardware. The --net path needs the vmnet entitlement and must run
under sudo for shared mode; without sudo it fails cleanly with a clear message. The
rootfs auto-brings-up eth0 and DHCPs on boot, so the guest reaches the internet with
no manual steps.
vmnet survives snapshot/restore: on restore the link is bounced and the guest’s carrier-watch re-runs DHCP. Each clone gets a distinct MAC and IP.
virtio-vsock
virtio-vsock carries stream connections between host and guest over the virtio
transport. E1 (guest→host) exposes per-port host listeners at {uds}_{port}: a guest
process connecting to a vsock port surfaces on the host as a connection to the matching
Unix socket path.
vsock host→guest (E2)
A host process opens a connection into a listening guest over the same control socket, using Firecracker’s hybrid protocol:
- The host connects to
{uds}(the base path of--vsock-uds) and sendsCONNECT <guest_port>\n. - ignition allocates an ephemeral host port, signals the guest (
REQUEST), and the guest’s listener accepts (RESPONSE). - ignition replies
OK <host_port>\nto the host; raw bytes then flow both ways on that same connection. If no guest process is listening, the connection is closed.
# guest init runs e.g.: socat VSOCK-LISTEN:5000,fork EXEC:cat
socat - UNIX-CONNECT:/tmp/ignition-vsock-e2 <<<'CONNECT 5000'
Guest→host (E1) and host→guest (E2) coexist; per-port paths {uds}_{port} remain the
E1 guest→host listeners.
For a full worked example with socat servers and clients on both ends, see the
vsock round-trip use case.
SMP
--smp N (default 1, cap 8) boots a real aarch64 Linux with N vCPUs. Secondaries come
online via PSCI CPU_ON, schedule work, and stop on SYSTEM_OFF. A VcpuManager
owns the linear MPIDR mapping (mpidr_for(index) = index) shared by the FDT,
MPIDR_EL1, and the CPU_ON claim guard; lazy bring-up spawns a thread-affine vCPU
per core. A restored guest reports nproc == N. The in-kernel hv_gic delivers
SGIs/IPIs and per-cpu vtimers natively, so secondaries need no VMM-side interrupt
plumbing.
target/debug/boot --smp 4 kimage/out/Image kimage/out/rootfs.ext4
# [ 0.010315] SMP: Total of 4 processors activated.
# (none):~# nproc
# 4
Clock
A PL031 RTC plus the EL1 virtual timer keep guest time. The vtimer PPI (INTID 27) is
delivered through the in-kernel GIC, and on restore the vtimer offset is set so that
CNTVCT resumes continuously across the snapshot rather than jumping forward.
GUI display
--gui provides a software-rendered desktop over virtio-gpu (2D, device id 16)
and virtio-input (keyboard + tablet, device id 18) with a cage Wayland compositor.
See GUI display for the full details: window threading model,
virtio-gpu/input kernel config, cage + foot setup, snapshot/restore/fan-out, and
window hotkeys (Ctrl+Alt+R reset, Ctrl+Alt+S snapshot, Ctrl+Alt+X close).
Related
- Device model — the trait these devices implement.
- Snapshot & restore — how device state survives a snapshot.
- GUI display — virtio-gpu, virtio-input, cage compositor, and window hotkeys.
GUI display (software-rendered)
boot --gui <kernel> <rootfs> opens a 1280x800 macOS window backed by a CPU
framebuffer (winit + softbuffer, no Metal). The Linux guest renders into the
window through a virtio-gpu device; a pair of virtio-input devices make the
window interactive; and the GUI rootfs runs a cage Wayland kiosk for a full
software-rendered desktop.
The macOS window
On macOS the winit event loop must own the main thread. Under --gui the entire
VMM — vCPU threads, the serial console reader, the vsock reactor, the vmnet RX
feeder — runs on spawned threads while the event loop runs on main. The window
title is “ignition” and its size is fixed at 1280x800 logical points (on a
Retina display the physical surface is larger; the blit path scales to fill).
The present path is non-blocking: frames arrive over an mpsc channel and are coalesced to the latest before each blit, so a slow or frozen window never backpressures the guest. The window holds its last frame between guest flushes (no flash to a clear color on idle redraws). Closing the window ends the session — the process exits and tears the disposable guest down. The serial console keeps working alongside the window throughout.
Without --gui (the default) — and for --restore and --fuzz — no window
opens and the vCPU loop runs on the main thread as before.
virtio-gpu (2D)
A virtio-gpu device (device id 16) is added under --gui. The Linux
virtio_gpu driver binds it, /dev/dri/card0 and /dev/fb0 appear, and the
kernel framebuffer console renders live in the macOS window. Two commands drive
the display path:
TRANSFER_TO_HOST_2D— copies guest pixels (scatter-gather correct) from guest RAM into a host-side buffer.RESOURCE_FLUSH— presents the scanned-out resource through the display sink, forwarding the frame to the winit event loop.
No 3D, VIRGL, or Venus support; no display resize or hotplug. GPU resource table and scanout binding are serialized as part of snapshot state (see below).
The guest kernel must be built with:
CONFIG_DRM=y
CONFIG_DRM_VIRTIO_GPU=y
CONFIG_DRM_FBDEV_EMULATION=y
CONFIG_FB=y
CONFIG_FRAMEBUFFER_CONSOLE=y
virtio-input
Under --gui, two virtio-input devices (device id 18) make the window
interactive: a keyboard (EV_KEY) and an absolute tablet (EV_ABS x/y +
buttons). The winit event loop translates host key/pointer/click events into
Linux evdev events and injects them into the guest’s eventq (inject_rx-style
path), so typing logs in at the console and the pointer tracks the macOS cursor
1:1 over the 1280x800 scanout.
Mouse position is scaled from the physical surface size to guest coordinates
(nearest-neighbor); button events map to BTN_LEFT/BTN_RIGHT/BTN_MIDDLE.
Physical key codes map to Linux evdev scan codes; unmapped keys are dropped
silently.
The guest kernel needs:
CONFIG_VIRTIO_INPUT=y
CONFIG_INPUT_EVDEV=y
Wayland compositor (cage + foot)
With the GUI rootfs (rootfs-gui.ext4, built by
kimage/build/build-rootfs-gui.sh), --gui runs a cage Wayland kiosk
(wlroots pixman software renderer — no GL, matching the 2D-only virtio-gpu)
hosting a foot terminal: an interactive software-rendered Linux desktop in
the macOS window, driven by the virtio-input keyboard + pointer.
The compositor path exercises fenced virtio-gpu commands — page-flips set
VIRTIO_GPU_FLAG_FENCE, and the device signals the fence in its response so
wlroots’s render loop keeps producing frames. Without fence signaling the
compositor renders one frame then stalls.
The minimal base rootfs has no compositor and uses the framebuffer console directly. The disposable browser swaps foot for Firefox ESR, with cage fullscreening the single browser window.
GUI snapshot, restore & fan-out
A --gui guest snapshots and restores like any other. Ctrl-A s writes a
complete snapshot of the live desktop (RAM, GIC, vCPU registers, device state),
and boot --gui --restore <name> reopens a window with the desktop resuming
where it left off. The virtio-gpu resource table and scanout binding plus the
virtio-input config cursor are serialized; pixels are not — on restore the device
re-reads the scanout from the restored guest-RAM backing and presents one frame,
so the window paints the resumed screen before the guest runs again.
Because each restore clones the immutable base into its own copy-on-write instance directory (keyed by pid), one warm-base snapshot fans out into N independent desktops, each with its own window:
# take one warm-base snapshot of a logged-in desktop (Ctrl-A s), then:
scripts/fanout-gui.sh 3 warm-base
# -> 3 boot --gui --restore processes, 3 windows, 3 isolated guests
Networking fans out too: with --net (needs sudo for vmnet shared mode) each
clone gets its own MAC and DHCP lease, since the GUI rootfs runs the same
netwatch carrier-poller as the base rootfs — every restore starts a fresh
vmnet interface, bounces the virtio-net link, and re-runs DHCP. Without the
poller a restored guest would keep the snapshot’s MAC.
sudo scripts/fanout-gui.sh 3 warm-base --net
See Snapshot & restore for the full mechanism, the
--track-dirty incremental path, and the read-only-disk requirement.
GUI window hotkeys
The focused window swallows keyboard input, so the serial Ctrl-A chords do not
reach the serial console FSM from the GUI window (they still work on a foreground
serial console when the window is not focused). Three Ctrl+Alt+<letter> chords
are intercepted by the window before the key reaches the guest:
| Hotkey | Action |
|---|---|
Ctrl+Alt+R | Cold reset (relaunch): the process exits with a sentinel code; a launcher (e.g. disposable-browser.sh) re---restores it from the snapshot. The window blinks and reopens at the warm state. Prints [gui] reset: relaunching clone from snapshot. |
Ctrl+Alt+S | Write a disk snapshot of the current desktop state. |
Ctrl+Alt+X | Close the window and end the session. |
Ctrl+Alt+R deliberately does not roll back in place under --gui. An in-place
rollback of a live, actively-rendering desktop cannot reconcile the running GIC and
virtio devices (net, vtimer, and the virtio-gpu fence pipeline) with the rolled-back
guest — hv_gic_set_state is create-time-only on HVF, so in-flight interrupt state
wedges the display/network under load. A fresh --restore (the relaunch) builds clean
device instances and the guest re-initialises, so it is reliable. The in-place reset
(Ctrl-A r on a serial console) is retained for headless guests, where it works.
The serial console still uses Ctrl-A x (quit), Ctrl-A s (snapshot), Ctrl-A b (reboot), Ctrl-A c (mark in-memory checkpoint), and Ctrl-A r (roll back
to checkpoint). See Snapshot & restore — interactive reset
for the full Ctrl-A c/r behaviour and the dirty-tracking detail.
Related
- Devices, SMP & networking — the virtio transport and device trait these devices build on.
- Snapshot & restore — full snapshot/restore/fan-out mechanism and interactive reset-to-checkpoint.
- Disposable browser — cage + Firefox over the same virtio-gpu/virtio-input stack.
- Device model — the
MmioDevicetrait.
Seatbelt sandbox
boot confines itself with a macOS Seatbelt profile applied to the process at startup
— self-sandboxing, no root required. The profile is embedded in the binary and active
by default on every run path (boot, restore, fuzz).
On by default; failure is fatal
The sandbox applies late in startup: after arguments are parsed, the kernel and rootfs are open, Hypervisor.framework is up, vmnet is started, and the vsock control socket is bound — immediately before the vCPU run loop begins. Threads already spawned at that point (vCPU, vmnet RX feeder, vsock reactor) come under the profile immediately; it is process-wide and irreversible.
Pass --no-sandbox to skip the apply. The flag is intentionally visible — the process
prints a loud warning and continues unconfined:
WARN: sandbox disabled (--no-sandbox) — VMM runs unconfined
If the profile fails to apply (the sandbox_init call returns non-zero), the process
prints the error and exits immediately:
FATAL: failed to apply sandbox: <errbuf text>
Fail-closed: the VMM never continues unsandboxed unless --no-sandbox is explicit.
The allowlist model — SandboxPaths
The sandbox crate assembles SandboxPaths from the already-parsed config before
calling apply. Two sets of paths are declared:
readable — host files the VMM legitimately reads at runtime:
- The kernel
Image - The rootfs image
- The initramfs (when present)
- The restore base directory (when restoring from a snapshot chain)
These are emitted as explicit (allow file-read* (subpath ...)) rules. They are
redundant under the current (allow default) base, but are already in place so a
future v2 deny-default flip requires no per-path changes.
writable — directories the VMM writes into at runtime:
- The snapshot store (
--store) /private/var/folders(the systemtemp_dir()root used for CoW-clone staging)- The vsock UDS parent directory (when
--vsock-udsis set) - Solutions directory (fuzz mode)
Writable paths are canonicalized and created if absent before the profile string is rendered; a canonicalization failure is a fatal error.
One subtlety on fresh boot: the rootfs is opened read+write by the virtio-blk driver
before the sandbox applies. Seatbelt checks file-write* at open() time, not on
writes through an already-open fd, so guest disk writes keep working even though the
rootfs path is not in the writable set. Restore writes a copy-on-write instance under
the store, which is covered directly.
What targeted-deny v1 confines
The profile is (allow default) with targeted denials carved out for the high-value
escape surfaces:
-
Network egress and ingress —
(deny network-outbound (remote ip))and(deny network-inbound (remote ip))block the VMM from opening IP sockets. vsock is AF_UNIX-local and is unaffected. vmnet moves L2 frames through vmnet.framework’s XPC/dispatch path (not a BSD socket in the VMM process), so guest networking is unaffected. -
Process execution and fork —
(deny process-exec*)and(deny process-fork)prevent a compromised VMM from spawning shells or helpers. -
Filesystem writes —
(deny file-write*)blocks all writes, then re-allows only/private/var/foldersand each canonicalizedwritablepath. Everything else on the host filesystem is write-denied. -
Host secrets —
~/.ssh,~/.aws,~/.gnupg,~/Library/Keychains, and/Library/Keychainsare denied for both read and write. This block is always emitted last in the profile. SBPL is last-match-wins, so the secret deny overrides any user-supplied--storepath that happens to overlap a secret directory.
What v1 does not yet confine
v1 leaves arbitrary host reads allowed (other than the secret directories listed above). A compromised VMM could still read most of the host filesystem. The full mach surface is also left open — that is what keeps HVF and vmnet.framework working without enumerating undocumented service names.
Closing that gap is the v2 plan: flip the base to (deny default) and grow an
explicit allow-list that covers the HVF and vmnet mach services. The readable paths
are already declared and emitted as explicit read-allows so that flip is a one-liner in
build_profile. A separate-uid privilege drop (needs a provisioned account and root) is
a further deferred follow-up.
Threat model
With v1: egress, exec, arbitrary writes, and host-secret reads are confined. “Your own code, your own machine” with a real process jail around the VMM. Multi-tenant or untrusted-workload positioning still waits on v2 (full read + mach confinement) and the uid drop.
Related
- Snapshot & restore — snapshot store paths that the sandbox keeps writable.
Disposable browser
ignition can run a throwaway Firefox ESR in a microVM where every write lands in guest RAM, never touches the disk, and a single hotkey resets the session back to a warm homepage — without reloading the kernel or replaying the overlay boot path. cage fullscreens the single Firefox window (so it fills the macOS window), but Firefox keeps its normal toolbar and address bar, so you can navigate anywhere.
What it is
Each browser session is an independent clone of a pre-warmed snapshot. The guest
boots once (the “cold boot”), Firefox opens on the homepage, and that moment is
frozen as the browser-base snapshot. From then on every session is a
sub-second restore: the kernel and overlay setup are already baked in. Closing
the window tears the clone down. The base snapshot is never mutated.
Fan-out is first-class: disposable-browser.sh -n N starts N independent
clones in parallel, each with its own macOS window, its own copy-on-write
instance directory, and (under --net) its own MAC address and DHCP lease.
The overlay-root model
The browser rootfs is designed to keep the backing ext4 image read-only
throughout the life of every session. On the cold boot, init=/sbin/overlay-init
runs before the normal init: it mounts the ext4 device read-only as the lower
layer of an overlay filesystem, places a tmpfs as the upper layer, and
switch_roots into the merged view. /tmp, the browser profile directory, and
any download paths all live in the tmpfs upper layer.
The consequence is that every write the guest makes — browser cache, cookies, history, tab state — lives in guest RAM and only in guest RAM. The ext4 image is never written.
This also means the warm-base snapshot needs no filesystem sync first: there are no dirty disk pages to flush (the disk is read-only), and the mutable filesystem state lives entirely in the tmpfs upper layer, which the RAM snapshot captures atomically once the vCPUs are parked. The read-only lower is shared unchanged.
This is what makes Ctrl-A r safe. The interactive reset-to-checkpoint
mechanism rolls back guest RAM, vCPU registers, GIC state, and virtio-device
state to a saved point. For that rollback to be correct, the disk must not have
diverged between the checkpoint and the reset. The overlay root guarantees this
invariant: there is nothing to diverge. As the snapshot-restore page puts it, the
intended usage “mounts the rootfs read-only and places all writable state on a
tmpfs overlay that lives in guest RAM” — that is exactly the arrangement
overlay-init establishes.
When boot --restore <dir> starts, the restored snapshot is automatically
installed as the initial reset point, so Ctrl-A r works from the first
keystroke without needing a prior Ctrl-A c.
Build rootfs-browser.ext4
The browser rootfs is built by kimage/build/build-rootfs-browser.sh. See
Building guest assets
for the full scp/ssh/scp workflow. The short version:
cd kimage
scp build/build-rootfs-browser.sh build/devmem.c artemis2:~/kbuild/
ssh artemis2 'cd ~/kbuild && chmod +x build-rootfs-browser.sh && HOMEPAGE=https://duckduckgo.com ./build-rootfs-browser.sh'
scp artemis2:'~/kbuild/out/rootfs-browser.ext4' out/rootfs-browser.ext4
The HOMEPAGE build argument sets the URL Firefox opens on first paint. The
rootfs ships overlay-init at /sbin/overlay-init, which the cold boot
activates via --append "ro init=/sbin/overlay-init".
Create the warm-base snapshot
This is a one-time step. After the warm base exists, sessions restore from it instead of cold-booting.
Helper script (recommended)
sudo scripts/make-browser-base.sh
The script cold-boots the browser rootfs with --gui --net --mem 2048 and
init=/sbin/overlay-init, watches the serial console for the
BROWSER_READY signal that the guest emits when Firefox has painted the
homepage, sends Ctrl-A s to snapshot the live guest as browser-base, waits
for the snapshot write to complete, then exits. No manual timing is required.
An optional snapshot name can be passed as the first argument:
sudo scripts/make-browser-base.sh my-base
Manual flow
If you prefer to watch the boot yourself and choose when to snapshot:
sudo target/debug/boot --gui --net --smp 2 --mem 2048 --name browser-base \
--append "ro init=/sbin/overlay-init" kimage/out/Image kimage/out/rootfs-browser.ext4
Pass --name browser-base so the snapshot you take is written under that name
(the name disposable-browser.sh restores by default). Wait for the Firefox
window to paint the homepage (the guest prints BROWSER_READY on the serial
console and the llvmpipe software renderer presents the first frame in the macOS
window). Once it looks right, press Ctrl-A s to
write the snapshot, then Ctrl-A x to quit. (Ctrl-A s writes immediately under
--name; there is no name prompt. Without --name the snapshot gets an
auto-generated name, which disposable-browser.sh will not find.)
The cold boot passes --append "ro init=/sbin/overlay-init" to hand control to
the overlay setup before normal init. Restore does not reload the kernel or re-run
the overlay pivot; it resumes from the frozen moment. (No --track-dirty: the GUI
reset is a relaunch, not an in-place rollback, so dirty tracking would only add
write-protect-fault overhead with no benefit.)
Run a disposable session
scripts/disposable-browser.sh
This restores one clone of browser-base: a GUI window opens with Firefox at
the homepage. Under the hood it runs:
target/debug/boot --gui --net --mem 2048 --restore browser-base
--net is included by default; because vmnet shared mode requires elevated
privileges, run under sudo when you want networking:
sudo scripts/disposable-browser.sh
Fan-out: N independent sessions
sudo scripts/disposable-browser.sh -n 3
This launches 3 clones in parallel, each with its own macOS window. Under
--net each clone gets a distinct MAC address and its own DHCP lease —
the browser rootfs carries the same netwatch carrier-poller as the GUI
rootfs, which rebinds virtio-net on restore and re-runs DHCP. Without
--net (no sudo) the clones are isolated but share the host network stack.
The base snapshot is never written; each clone’s copy-on-write instance
directory is private and keyed by the clone’s pid. Closing a clone’s window
tears down only that guest. If the script is killed with Ctrl-C it cleans
up all child processes.
A non-default base name or additional boot flags can be passed after the
clone count:
sudo scripts/disposable-browser.sh -n 2 my-base --store /data/vmstore
Reset a session
With the browser window focused, press Ctrl+Alt+R to reset the clone back to
the warm homepage, Ctrl+Alt+S to write a disk snapshot, and Ctrl+Alt+X
to close the window. (These are window hotkeys, intercepted before the keystroke
reaches the guest; disposable-browser.sh runs each clone backgrounded, so the
serial Ctrl-A chords never reach it.)
Ctrl+Alt+R is a cold reset (relaunch): the clone process exits with a sentinel
code and disposable-browser.sh re---restores it from the snapshot — the window
blinks and reopens at the warm homepage in roughly the cold-restore time (~hundreds
of ms; see the latency benchmark). Everything
from the session evaporates because the restored clone starts from the immutable
warm-base again.
Why relaunch rather than roll back in place: an in-place rollback of a live,
actively-rendering GUI guest cannot reconcile the running GIC and virtio devices
(net, vtimer, and especially the virtio-gpu fence pipeline) with the rolled-back
guest state — hv_gic_set_state is create-time-only on HVF, so in-flight interrupt
state wedges the display/network under load. A fresh --restore has none of that
(it builds clean device instances and the guest re-initialises), so it is the robust
reset for the GUI. The in-place reset (Ctrl-A r on a serial console) is retained
for headless guests where it works.
Memory and resource footprint
--mem 2048 (2 GiB) is the default for both make-browser-base.sh and
disposable-browser.sh — 1 GiB OOMs Firefox once the tmpfs overlay (profile,
cache, /tmp) fills under real browsing. For N clones the RAM cost is approximately N GiB of
guest-visible address space, though Apple Silicon memory compression and the
CoW instance directories mean the actual resident footprint is lower in
practice. The rootfs-browser.ext4 disk image is shared read-only across all
clones — only the per-clone tmpfs upper layer (in guest RAM) diverges.
The warm-base is created with --smp 2 (Firefox is happier with more than one
core). The vCPU count is baked into the snapshot, so every restored clone gets
those 2 cores automatically — disposable-browser.sh does not pass --smp
because restore inherits the count from the snapshot (like --mem). Re-create
the warm-base with a different --smp value to change it.
Related
- Snapshot & restore — the restore and fan-out mechanism,
and the full
Ctrl-A c/Ctrl-A rinteractive checkpoint behaviour. - Devices, SMP & networking —
--gui,--net, virtio-gpu, and thenetwatchcarrier-poller. - Building guest assets — kernel config requirements and the artemis2 build workflow.
VM internal API (MMIO)
Guest code talks to the VMM through fixed guest-physical MMIO regions. No virtio,
no syscall, no shared filesystem: the guest maps a device’s region from /dev/mem
at a known GPA and reads/writes registers directly. The VMM either traps the access
(control registers) or hands the guest plain RAM it also maps host-side (data
windows).
Two devices expose this interface today: the boot-timer (a one-shot signal) and
the fuzz device (a full control protocol). Both regions sit below RAM_BASE
(0x4000_0000) so they are outside guest RAM and outside snapshot/reset tracking.
Access rules for guests:
mmapthe containing page of/dev/memat the region’s GPA. Offsets must be 16 KiB-aligned (the guest page granule), which every GPA below already is.- Use a single naturally-sized access at the register offset. The width matters for
trap-MMIO registers, so
ddis not a substitute. Adevmem-style tool or a typedvolatilestore is correct.
Boot-timer
A one-shot pseudo-device. The guest writes the magic byte 123 as an 8-bit store
to offset 0 once at the end of boot; the VMM records elapsed wall time since VM start
and logs Guest-boot-time = N ms. Repeat writes are ignored. No FDT node, no
interrupt, no snapshot state.
| Field | Value |
|---|---|
| GPA | 0x091F_F000 |
| Access | 8-bit write, offset 0 |
| Magic value | 123 |
The stock rootfs signals it from /etc/local.d/boottime.start:
devmem 0x091FF000 8 123
The equivalent in C (the devmem tool’s core: map the page, do one uint8_t store):
#include <fcntl.h>
#include <stdint.h>
#include <sys/mman.h>
#include <unistd.h>
#define BOOT_TIMER_GPA 0x091FF000UL
#define BOOT_COMPLETE 123
int main(void) {
int fd = open("/dev/mem", O_RDWR | O_SYNC);
if (fd < 0) return 1;
/* map the 16 KiB page containing the register */
volatile uint8_t *reg = mmap(0, 0x4000, PROT_READ | PROT_WRITE,
MAP_SHARED, fd, BOOT_TIMER_GPA);
if (reg == MAP_FAILED) return 1;
reg[0] = BOOT_COMPLETE; /* single 8-bit store -> VMM logs the boot time */
return 0;
}
Fuzz device
The fuzz device carries the in-VMM fuzzing loop. It has three regions: a trapping
control region (registers), a RAM-backed input window (host writes the input,
guest reads it), and a RAM-backed coverage map (guest writes 8-bit SanCov edge
counters, host reads them). The canonical constants live in
crates/devices/src/fuzz/protocol.rs; the guest mirror is
kimage/build/fuzz-harness/ignition_fuzz.h.
Memory map
| Region | GPA | Size | Backing |
|---|---|---|---|
| Control registers | 0x0920_0000 | 16 KiB | trap-MMIO |
| Input window | 0x0920_4000 | 2 MiB (default) | shared RAM |
| Coverage map | 0x0940_4000 | 64 KiB | shared RAM |
Control registers
| Offset | Name | Access | Meaning |
|---|---|---|---|
0x00 | DOORBELL | W | guest writes a command code; the store traps to the VMM |
0x04 | INPUT_LEN | RW | length of the current input in the window (host writes, guest reads) |
0x08 | CRASH_CODE | W | abort/sanitizer reason class, written before a CRASH doorbell |
0x0c | STATUS | R | VMM-to-guest handshake (optional) |
Doorbell commands (guest → VMM)
| Code | Name | Meaning |
|---|---|---|
0x1 | SNAPSHOT_ME | one-time setup complete, parked at the parse site; first receipt captures the snapshot |
0x2 | DONE | input processed cleanly |
0x3 | CRASH | target crashed (rung from the sanitizer/signal handler) |
Guest harness (C)
The harness maps the three regions, then loops: read the input length, run the
target over the window, ring DONE. The VMM resets the guest to the snapshot after
each doorbell. Excerpt from kimage/build/fuzz-harness/harness.c:
#include "ignition_fuzz.h"
static volatile uint8_t *g_ctrl; /* control registers */
static volatile uint8_t *g_win; /* input window */
static volatile uint8_t *g_cov; /* coverage counters */
static inline void reg_write(unsigned off, uint32_t v) {
*(volatile uint32_t *)(g_ctrl + off) = v;
}
static inline uint32_t reg_read(unsigned off) {
return *(volatile uint32_t *)(g_ctrl + off);
}
static inline void doorbell(uint32_t cmd) { reg_write(REG_DOORBELL, cmd); }
int main(void) {
int fd = open("/dev/mem", O_RDWR | O_SYNC);
g_ctrl = mmap(0, IGNITION_FUZZ_CTRL_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, IGNITION_FUZZ_CTRL_GPA);
g_win = mmap(0, IGNITION_FUZZ_WIN_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, IGNITION_FUZZ_WIN_GPA);
g_cov = mmap(0, IGNITION_FUZZ_COV_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, IGNITION_FUZZ_COV_GPA);
/* one-time setup is done; park here -- the snapshot/reset PC lands just after. */
doorbell(CMD_SNAPSHOT_ME);
for (;;) {
uint32_t len = reg_read(REG_INPUT_LEN);
if (len > IGNITION_FUZZ_WIN_SIZE) len = IGNITION_FUZZ_WIN_SIZE;
target_parse((const uint8_t *)g_win, (unsigned long)len); /* the code under test */
doorbell(CMD_DONE);
}
}
A crash is reported the same way, from a sanitizer death callback or a fatal-signal handler, before the VMM rolls the guest back:
static void on_crash(int reason) {
reg_write(REG_CRASH_CODE, (uint32_t)reason);
doorbell(CMD_CRASH);
for (;;) { /* the VMM resets us out of this loop */ }
}
Related
- Device model — how these devices register on the MMIO bus.
- How snapshot fuzzing works — the loop the fuzz device drives.
- Running the fuzzer — building and driving the harness.
How snapshot fuzzing works
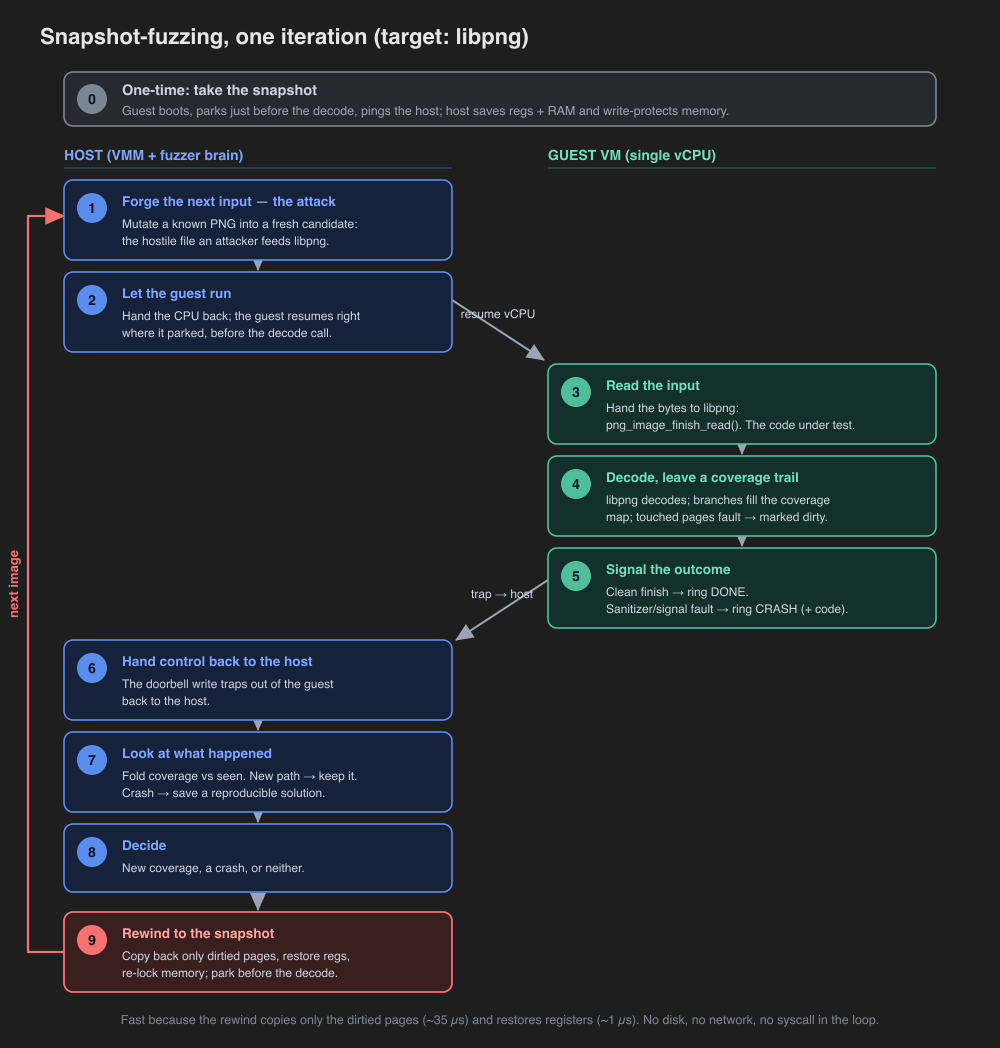
In-VMM snapshot fuzzer for ignition (Firecracker-modeled microVM on Apple
Hypervisor.framework). The fuzzer parks the guest at a parse entry, injects
inputs into a shared window, runs the target, and resets the guest to the
snapshot every iteration via hv_vm_protect dirty-page tracking, all without
leaving the VMM. This is the M3 benchmark: real libpng-current as the target,
single core.
Date: 2026-06-14. Host: Apple Silicon, macOS 26.5. Guest: aarch64, 128 MiB, single vCPU, 16 KiB page granule. Target: libpng 1.6.43 + zlib 1.3.1, built with SanCov edge coverage, no AddressSanitizer (see Methodology).
Throughput and reset
| Metric | libpng (dirty reset) | libpng (full-copy reset) |
|---|---|---|
| Steady-state execs/sec | 1309 | 271 |
| Reset latency p50 | 36 us | — |
| Reset latency p99 | 60 us | — |
| page-copy p50 | 35 us | — |
| register-restore p50 | 1 us | — |
Dirty reset is 4.8x the full-copy reset on the same target. The reset cost is dominated by the page copy; register restore is about 1 us.
Dirty-set size (pages dirtied per iteration, 16 KiB each)
| p50 | p99 | max |
|---|---|---|
| 44 | 50 | 50 |
The dirty set is what the reset copies back; it explains the page-copy latency above and feeds the diff-snapshot work.
Coverage
Distinct edges hit: 144 (SanCov trace-pc, hashed into the reset-exempt
coverage window). The coverage-over-time curve is the covsample series in the
metrics file (--metrics).
Correctness (deterministic)
Time-to-rediscover the planted heap overflow (synthetic ASan target, a
CVE-shaped chunk parser): 0.002 s from a seed corpus, deterministically
replayable from the saved input (--replay). This is the M1 correctness number,
re-measured here as the deterministic anchor alongside the throughput numbers.
Methodology
- Coverage-only libpng build. The throughput, reset, and dirty-set numbers come from a SanCov-only libpng build (no ASan). Per the design’s section 12 risk note, ASan shadow (1/8 of the working set) joins the dirty set and inflates reset; a coverage-only build isolates the snapshot machinery. The deterministic bug-finding number uses the separate ASan build.
- Single core, steady state. execs/sec is measured over a fixed wall-clock window after warm-up; SIGINT triggers a clean metrics flush.
- Reproduce:
M3_DURATION=60 python3 scripts/fuzz_m3_bench.py(needs a signedboot,kimage/out/Image, and both fuzz initramfs images; seeREBUILD-GUEST-ASSETS.md).
See Running the fuzzer for the build, the gate scripts, and every
boot --fuzz flag.
Related
- Running the fuzzer — gates, flags, and the benchmark driver.
- The clone primitive — the in-loop
reset()this loop depends on. - Snapshot-fuzzing benchmark — the throughput numbers.
Running the fuzzer
This chapter covers the build, the three gate scripts, the benchmark driver, and
every boot --fuzz flag. For the design and the measured numbers see
How snapshot fuzzing works. For the kernel image and the two fuzz
initramfs images (synthetic ASan target and the libpng target) see
Building guest assets.
Build and sign
The fuzzer lives in the boot binary of the ignition-spike crate. Build it,
then code-sign with the Hypervisor.framework entitlement (macOS will not let an
unsigned binary call hv_vm_create):
$ cargo build -p ignition-spike --bin boot
$ scripts/sign.sh target/debug/boot
Every command below assumes the signed target/debug/boot, a kernel at
kimage/out/Image, and the matching initramfs image already present.
Gates
Three Python drivers run the binary end to end. They locate the artifacts via
BOOT_BIN, FUZZ_KERNEL, and the FUZZ_INITRAMFS* environment variables and
fall back to the default paths above.
M1: rediscover the planted bug, deterministically
$ python3 scripts/fuzz_m1_test.py
Boots the fuzzer with a near-boundary seed (a valid FUZ chunk, length 16) and
checks that blind havoc bumps the length field past the buffer, trips the
sanitizer, and writes a solution file. Then it replays the saved crash input
verbatim and confirms it re-crashes. This is the correctness anchor.
M2: coverage feedback plus dirty-page reset
$ python3 scripts/fuzz_m2_test.py
Asserts that coverage grows above its first reading and the corpus expands past the single seed, that the planted bug is still found through the dirty reset and replays deterministically, and that dirty-reset execs/sec beats full-copy execs/sec on equal wall-clock.
M3: the benchmark
$ M3_DURATION=60 python3 scripts/fuzz_m3_bench.py
Runs three fixed-wall-clock passes against real libpng (dirty reset, then
full-copy reset for the speedup ratio) and the synthetic ASan target (for
time-to-rediscover), parses the metrics file, and gates that the machinery
produced usable numbers. M3_DURATION (seconds) and M3_MEM (guest MiB) tune
the run.
Driving boot --fuzz directly
The gate scripts wrap this invocation. A representative direct run:
$ target/debug/boot --fuzz \
--initramfs kimage/out/fuzz-initramfs-libpng.cpio \
--reset dirty \
--seed corpus/seed.png \
--metrics /tmp/fuzz-metrics.txt \
kimage/out/Image
SIGINT (Ctrl-C) stops the loop and flushes the metrics file cleanly.
--reset dirty|full
How the guest RAM is rolled back between iterations.
dirty(default): per-iteration dirty-page rollback.hv_vm_protectwrite-protects guest RAM; the first write to each 16 KiB page traps, marks the page dirty, and re-grants write access. The reset copies back only that dirty set, then restores the vCPU registers.full: the full-RAM-copy baseline. Every iteration copies the entire guest RAM from the snapshot regardless of what changed. Correct and simple, and the reference point the dirty reset is measured against.
--metrics <path>
On clean shutdown the controller writes a metrics file at <path> containing:
execs/sec: steady-state throughput.- reset-latency p50 and p99, split into the page-copy cost and the register-restore cost (the page copy dominates; register restore is about 1 us).
- the dirty-set-size distribution (pages dirtied per iteration, p50/p99/max).
- the coverage curve, emitted as a series of
covsamplelines (timestamp, distinct edges) so the coverage-over-time growth is plottable. - time-to-rediscover the planted bug, the deterministic correctness number.
Other flags
--initramfs <path>: the guest root image, which selects the target. Use the synthetic ASan image for bug-finding and correctness, or the libpng image for the throughput benchmark; see Building guest assets.--seed <path>: a seed corpus input the fuzzer starts from.--solutions <dir>: where crash inputs are written.--replay <path>: replay a saved input once instead of fuzzing, to confirm a crash reproduces deterministically.--mem <MiB>: guest RAM size.
Boot & restore latency
Status note (2026-06): numbers predate the fast-restore work. Restore latency here was measured with eager
read(memory.bin); restore now uses clonefile +mmap(MAP_SHARED)(lazy, immutable base) and is materially faster — these figures are pre-fast-restore. The--store/--namestore convention, multi-vCPU snapshot, and re-snapshot post-date this doc.
Date: 2026-06-13. Host: Apple Silicon, macOS 26.5. Guest: aarch64 Linux 6.1
(Firecracker CI microvm config + virtio-balloon/vsock/devmem), Alpine 3.19 busybox
rootfs, single vCPU, 512 MiB RAM. Warm page cache. n = 6 (scripts/benchmark.py 6).
These are ignition-internal numbers (fresh boot vs snapshot restore). Cross-VMM comparison (KVM Firecracker, Apple Virtualization.framework) is future work.
Two measurement methods (and what each captures)
Boot/restore latency depends on where you start and stop the clock. We use two complementary methods rather than one:
-
Guest-boot-time— the boot-timer device (Ctrl-less, automatic). The guest’s init pokes a magic byte to a fixed MMIO address at the end of early boot; the VMM timestamps it relative to VM start. This measures kernel + early-init readiness from inside the guest’s time domain — it excludes host-side process spawn and is independent of how long the rest of userspace (getty, login) takes. This is Firecracker’s own boot-time metric, ported. -
launch → login:— the host harness (scripts/benchmark.py). Wall-clock fromexec(boot)until thelogin:prompt bytes appear on the console. This measures time to an interactive shell end-to-end: host process spawn, kernel load into guest RAM, FDT generation, HVF setup, the full kernel boot, and all of openrc init through to getty.
For restore there is a third clock:
Restore-time— host-side (logged inrun_restore). Wall-clock fromboot --restoreentry until the restored guest is handed to the run loop:mmap+ loadmemory.bin(512 MiB) + GIC/device/vCPU state restore. The boot-timer device cannot measure restore — the guest’s init does not re-run on restore — so this host-side clock is the restore analog ofGuest-boot-time.
Results (n = 6)
| Phase | Metric | mean | min | max |
|---|---|---|---|---|
| Fresh boot | Guest-boot-time (boot-timer, VM-start → init ready) | 204 ms | 193 | 214 |
launch → login: (host wall, to interactive shell) | 1.24 s | 1.23 | 1.25 | |
| Restore | Restore-time (host-side, RAM load + state restore) | 115 ms | 93 | 148 |
| launch → restored prompt (host wall) | 0.53 s | 0.50 | 0.55 |
Interpretation
-
Kernel readiness vs shell. The two fresh-boot numbers differ by ~6× (204 ms vs 1.24 s) precisely because they measure different things: the kernel + early init reach the boot-timer poke in ~200 ms, but reaching a usable
login:prompt (host process spawn + the rest of openrc init + getty) takes ~1.24 s wall. Reporting only one would mislead — “boots in 200 ms” (kernel) and “1.2 s to a shell” (end-to-end) are both true and answer different questions. -
Restore beats fresh boot. Bringing a fully-booted guest back to a running state costs ~115 ms (host-side) — about 1.8× faster than the 204 ms kernel boot and ~11× faster than the 1.24 s boot-to-shell, because restore skips the entire kernel boot + init sequence and only replays memory + device/vCPU state.
-
Restore cost is RAM-load-bound and flat. The 115 ms is dominated by copying the 512 MiB
memory.bininto the guest mapping; it scales with RAM size, not with how much the guest does at startup. A heavier guest (more services, larger init) inflates the fresh-boot numbers but leaves restore roughly unchanged — so the restore advantage widens for real workloads beyond this minimal Alpine rootfs.
Caveats
- Warm page cache.
memory.binand the kernel image are in the host page cache; a cold restore adds disk-read time to the 115 ms. launch → restored prompt(0.53 s) is harness-quantized. The restored guest is running at ~115 ms (Restore-time); the 0.53 s is the benchmark nudging the getty to redraw its prompt on a 0.5 s cadence, not a true readiness cost. UseRestore-timeas the restore latency; treat→ promptas an upper bound.- Clock domains differ.
Guest-boot-timeis stamped inside the VMM relative to VM start (≈ vCPU creation);launch → login:is host wall fromexec, including ~tens of ms of process spawn before the VM exists. They are complementary, not subtractable. - Minimal guest, single vCPU, 512 MiB. Small kernel + busybox init → unusually fast boot; absolute numbers will grow with a fuller guest. Multi-vCPU and incremental/dirty-page snapshots are not measured (out of scope).
Reproduce
cargo build -p ignition-spike --bin boot && scripts/sign.sh target/debug/boot
python3 scripts/benchmark.py 6 # both fresh-boot methods + restore
# component scripts:
python3 scripts/boot_vs_restore_timing.py # launch -> running, phased
python3 scripts/restore_test.py # snapshot -> restore, CPU% + responsive
Disposable browser latency
Date: 2026-06-16. Host: Apple Silicon, macOS 26. Guest: the browser rootfs
(rootfs-browser.ext4) — overlay root, Firefox ESR under cage, 2 vCPUs, 1 GiB,
--gui --net --track-dirty. Three operations, all in ms, n = 3
(scripts/disposable_browser_bench.py for the first two; hot restore measured by hand
— serial input does not reach the escape FSM under --gui, so the in-place reset is
driven from the GUI window with Ctrl+Alt+R).
Config note: the “hot restore” (in-place
Ctrl+Alt+R) figures below were taken on the now-superseded in-place GUI reset, with--track-dirtyat 1 GiB. The GUI reset is now a cold reset (relaunch) —Ctrl+Alt+Rexits and the launcher re---restores the clone, i.e. the flat ~130 ms cold-restore path — because in-place rollback wedged the live display under load (see below). The browser now runs at 2 GiB without--track-dirty. The in-place figures are retained as the evidence for that switch.
| Operation | What it is | mean | range |
|---|---|---|---|
Cold boot → BROWSER_READY | full kernel boot + overlay switch_root + Firefox cold start, to a painted homepage (wall) | 7774 ms | 7618–8084 |
Cold boot — Guest-boot-time | kernel + early init only (guest time domain) | 599 ms | 536–724 |
Cold restore — Restore-time | a fresh boot --restore browser-base process: clonefile + mmap(MAP_SHARED) + GIC/device/vCPU state restore, before the guest runs | 130 ms | 127–131 |
| GUI reset (cold/relaunch) — current | Ctrl+Alt+R exits + the launcher re---restores → ≈ cold restore + window recreate | ≈130 ms + window | — |
In-place reset — Reset-time (serial/headless; superseded for GUI) | in-place rollback of a running clone (dirty-page revert + device restore + repaint), after browsing to a real page | 100–1220 ms | (working-set dependent) |
One cold-restore tail breakdown (132 ms total): dev:93ms (recreating the virtio
set — gpu/net/blk/input — dominates) + stdin:39ms; everything else is sub-ms.
Interpretation
-
Cold restore is ~60× faster than cold-booting to a usable browser (130 ms vs ~7.8 s). That gap is the disposable-browser value proposition: the warm snapshot skips Firefox’s ~7 s cold start. Cold restore is also remarkably flat (127–131 ms) because
clonefile+mmap(MAP_SHARED)does no large up-front read — the working set faults in lazily as the restored browser runs. -
The GUI reset is now a cold relaunch ≈ the flat 130 ms cold-restore plus a window recreate. It is reliable because a fresh
--restorebuilds clean device instances and the guest re-initialises — none of the live-state reconciliation that broke the in-place path. The in-place figures below are the (now serial/headless-only) reset that motivated this switch. -
In-place reset cost scaled with the dirtied working set under
--track-dirty— the dirty-only rollback synchronously copies the pages dirtied since the checkpoint, page-by-page, plus a full re-protect. Right after loading a heavy page the first reset was 1220 ms; subsequent resets fell to 207 → 100 ms. -
Full-copy is faster warm but not viable for the GUI. A no-
--track-dirtyreset is a single sequential full-RAM copy — lower warm latency than the scattered dirty-only copy — but it reverts the live virtio-gpu/input ring + fence state out from under the still-running window (the GUI host threads are not quiesced during the rollback), which wedges the display (cage blocks invirtio_gpu_queue_fenced_ctrl_buffer). Dirty-only reverts a smaller, more consistent subset and keeps the window alive, so it is retained. -
In-place reset of a live, actively-rendering GUI is fundamentally fragile on HVF. Rolling back guest RAM + vCPU state while the GIC and the virtio devices stay live leaves in-flight interrupt state unreconciled — surfacing in turn as net (
not a head), vtimer (RCU stall), and GPU-fence (cage hang) wedges, becausehv_gic_set_statecannot be re-applied mid-run. This is why the GUI reset is a relaunch (tear down + a fresh--restore, the flat 130 ms cold path) rather than an in-place rollback — it sidesteps all of it. In-place reset is kept only for headless/serial guests, where it works. -
Known cosmetic warning (non-fatal): after an in-place reset under active traffic the guest may log
virtio_net … not a head. Root-caused via instrumentation: the rollback is complete (each reset reverted 600 MB–1 GB of dirtied pages, no malformed heads), so this is not corruption. The warm-base snapshot froze the net RX queue mid-flight (the device had completed RX into descriptors and advancedused.idxbefore the guest drained them); the in-place reset replays those completions on resume — and one descriptor is no longer a chain head in the rolled-back state, so the guest drops it (the warning) before the carrier-bounce rebind re-inits the NIC and re-DHCPs. A cold restore never hits it because the guest rebinds first. It self-heals; net works after. (A net-idle warm-base snapshot would remove it at the source.)
Related
- Snapshot & restore — the feature these numbers measure.
- Disposable browser — the workload behind the latency table above.
- Snapshot-fuzzing benchmark — execs/sec as a direct readout of reset latency.
Diff-snapshot benchmarks
Date: 2026-06-13. Host: Apple Silicon, macOS 26.5. Guest: aarch64 Linux, busybox
rootfs, single vCPU, 512 MiB RAM, 16 KiB guest pages. Numbers are the median
of 3 runs unless noted, with min/max in parentheses. Harness:
scripts/diff_snapshot_bench.py (pty console driving, time.monotonic() clocks).
Snapshot-write times were re-measured (2026-06-13) with an in-process VMM timer (
Snapshot-write-time), correcting an earlier console-poll artifact. See §2 — a Diff (17–58 ms) is much faster to write than a Full (147 ms); the old ~317–372 ms band was rendezvous + console + poll overhead, not the write. The AC-comparison write rows further down are the old (superseded) numbers, kept only for the power-sensitivity point and flagged as such.
Power state: the headline tables below were measured on battery. A full re-measurement on AC power (
pmset -g batt= “AC Power”;pmset -g thermreported no thermal/performance warnings) reproduced the same medians within run-to-run noise — every metric inside ±~10 %, and the prime suspects (dd write throughput, dd fault tax) did not improve on AC. So on this host the power source did not materially affect these metrics. See “Re-measured on AC power” at the end for the side-by-side. The numbers in the tables stand as-is.
Debug build. All headline numbers are an unoptimized
target/debug/boot(cargo buildwith no--release). A release data point is included at the end — and, perhaps surprisingly, release is within noise of debug for these metrics: they are I/O- and guest-bound, not VMM-CPU-bound. Still treat absolute milliseconds as figures from this host, not portable production latency.
This doc is a focused follow-up to Boot & restore latency (which measured plain boot vs restore and predates the diff-snapshot feature). It quantifies the cost and benefit of diff/incremental snapshots specifically.
What each timer brackets
| Timer | Brackets |
|---|---|
Guest-boot-time (boot-timer device) | VM start → guest init pokes the boot-timer MMIO byte. Kernel + early init, in the guest time domain. |
| boot wall | host spawn() of boot → login: bytes on the console. End-to-end to an interactive shell. |
| dd MB/s | busybox dd writing 64 MiB to /dev/shm (RAM tmpfs); dd’s own reported rate. The write-protect fault tax shows here. |
| snapshot write | Ctrl-A s written to the pty → the handler prints [snapshot] full|diff '<name>' … written. |
Restore-time (host log) | boot --restore entry → restored guest handed to the run loop (base mmap + chain overlay + GIC/device/vCPU state). |
| restore wall | host spawn() of boot --restore → first non-empty console byte after we poke Enter. |
1. Dirty-tracking runtime overhead
1a. Boot time — without --track-dirty vs with
| Metric | Untracked | --track-dirty |
|---|---|---|
Guest-boot-time (boot-timer) | 202 ms (190–221, n=3) | 214 ms (211–584, n=3) |
boot wall → login: | 1241 ms (1225–1264, n=3) | 1256 ms (1254–1624, n=3) |
Tracking adds little to boot. Both medians move ~10–15 ms — within run-to-run noise. The tracked column has one cold outlier each (584 ms / 1624 ms on the first tracked run); the two steady-state runs are ~211–214 ms / ~1254–1256 ms, on top of untracked ~202 ms / ~1241 ms. The write-protect arming happens once around boot and the guest faults pages in lazily, so boot-to-login does not pay a big up-front tracking tax here.
1b. In-guest write throughput — without vs with tracking
dd if=/dev/zero of=/dev/shm/blob bs=1M count=64 (64 MiB into a RAM-backed tmpfs;
the rootfs ext4 is 100 % full so a disk write is impossible, and tmpfs is the right
target to expose the RAM write-protect fault).
| Untracked | --track-dirty | |
|---|---|---|
| dd throughput | 2100 MB/s (2100–2200, n=3) | 1500 MB/s (1500–3600, n=3) |
The write-protect fault tax is real but noisy. Median throughput drops ~28 % (2100 → 1500 MB/s) under tracking, because each first write to a clean page traps out of write-protect before the store completes. But the spread is wide — one tracked run measured 3600 MB/s (higher than untracked), so the signal is partly swamped by tmpfs/host scheduling noise on a single 64 MiB pass. The tax is a per-page, first-touch cost; on a workload that re-writes already-dirty pages it disappears. Read this as “tracking can cost roughly a quarter of first-touch write bandwidth,” not a precise constant.
2. Snapshot write time — Full vs Diff
Measured by an internal VMM timer (Snapshot-write-time = N ms, logged by
write_named_snapshot / write_named_diff) that brackets exactly the write work:
write_snapshot/write_diff_snapshot (memory + GIC + vmstate.json + disk.img
clonefile) plus the manifest. Full is a fresh-boot root (whole 512 MiB RAM); Diffs are
taken after dirtying a bounded region, against a kept golden root.
| Snapshot | dirtied | dirty pages | write time |
|---|---|---|---|
| Full root (512 MiB RAM) | — | (whole RAM) | 147 ms (124–195, n=5) |
| Diff | 8 MiB | ~903 | 17 ms (14–36, n=5) |
| Diff | 64 MiB | ~4552 | 58 ms (30–64, n=5) |
A Diff is much faster to write than a Full — the write cost is proportional to
bytes written, exactly as expected. The Full path streams the whole 512 MiB
(write_all) in ~147 ms; the Diff path packs only the dirtied 16 KiB pages — ~15 MB
at 8 MiB dirtied → ~17 ms (≈ 8.6× faster), ~75 MB at 64 MiB dirtied → ~58 ms
(≈ 2.5× faster). Roughly linear in packed pages: (58 − 17) ms over (4552 − 903) pages
≈ ~11 µs per packed 16 KiB page, consistent with bulk memcpy + sequential write.
Measurement correction. An earlier revision reported all three writes in a tight ~317–372 ms band and concluded a Diff “is NOT meaningfully faster to write.” That was a harness artifact: the old timer bracketed
Ctrl-A skeystroke → console line using a 300 ms drain-poll, so it folded in the vCPU stop-the-world rendezvous, console latency, and up to 300 ms of poll quantization — none of which is the write. With the in-process timer the write itself is 17–147 ms and clearly bytes-proportional. The ~300 ms a human sees after pressingCtrl-A sis real, but it is rendezvous + console, not the snapshot write.
So the diff payoff is both disk footprint and write latency (plus chain semantics).
3. Restore latency — by chain depth
Restoring a Full-only base (1 layer), golden + 1 diff, and golden + 3 diffs. Each
diff layer adds a read_diff_pages + apply_diff memcpy overlay before vCPUs run.
| Restore target | layers | Restore-time (internal) | restore wall (→ first output) |
|---|---|---|---|
| Full only (golden) | 1 | 245 ms (240–247, n=3) | 257 ms (254–257, n=3) |
| golden + 1 diff (d1) | 2 | 243 ms (237–245, n=3) | 258 ms (254–259, n=3) |
| golden + 3 diffs (d3) | 4 | 242 ms (242–244, n=3) | 257 ms (256–258, n=3) |
Restore latency is flat across chain depth. 1 layer and 4 layers restore in the
same ~242–245 ms internal / ~257 ms wall — the per-layer overlay is lost in the
noise. Reason: each diff here is only ~900 pages (~14 MB), so apply_diff is a tiny
memcpy on top of the dominant cost (mapping the 512 MiB base + replaying GIC/device/
vCPU state). The cost would grow with very large or very many diffs (each layer’s
dirty pages are read + copied), but for shallow chains of small deltas it is
effectively free. Restore also beats fresh boot here (~245 ms vs ~1241 ms boot-to-
shell) because it skips the kernel + init sequence entirely.
Where the ~245 ms goes (per-stage median, µs):
| stage | Full-only | golden+3 |
|---|---|---|
| chain resolve+validate | 238 | 356 |
| read leaf state | 556 | 465 |
| clonefile root RAM | 489 | 391 |
| mmap | 79 | 74 |
| diff overlay | 0 | 75451 |
| Vm::new (hv_vm_create) | 138 | 64 |
| HvfGicV3::new (hv_gic_create) | 1200 | 556 |
| map_memory (hv_vm_map) | 10 | 3 |
| protect | 0 | 0 |
| device wiring | 531 | 216 |
| total | 244040 | 243310 |
The named stages sum to only ~3.2 ms (Full-only) / ~78 ms (golden+3) of the ~244 ms
total. A finer bisection of the restore tail (the Restore-tail log line) localizes
the remaining ~240 ms precisely:
golden #0: dev:2757us vsock:1us freeze:2us console:240591us handler:19us dirty:0us stdin:79us net:30us total:243483us
golden #1: dev:3774us vsock:0us freeze:0us console:237500us handler:22us dirty:0us stdin:84us net:61us total:241444us
golden #2: dev:3319us vsock:1us freeze:0us console:240354us handler:17us dirty:0us stdin:112us net:33us total:243840us
The console probe brackets just two trivial statements — TermiosGuard::new() (four
non-blocking termios syscalls) and VcpuManager::new() (a struct alloc) — yet it holds
~240 ms. Neither touches guest RAM or blocks. The cost is hv_vm_map making the full
512 MiB MAP_SHARED CoW clone resident, eagerly, before any vCPU runs. map_memory
(hv_vm_map) itself returns in ~10 µs, but the region is materialized as a side effect
that lands on the following syscalls.
Proof it is full-RAM materialization, not the tail code: the total is depth-invariant
and trades off against early page touches. For golden (no diff) the ~240 ms sits in the
post-map tail; for golden+3 the apply_diff overlay pre-touches its pages, so ~75 ms
shifts into the diff stage and the tail drops by the same amount — total stays
~243 ms.
This overturns a documented assumption. The README and earlier notes said restore “touches only used pages” (lazy). It does not: restore materializes all guest RAM before the guest runs, so
Restore-timeis dominated by a fixed full-RAM cost (~240 ms for 512 MiB here) that is independent of the guest’s working set and of diff chain depth.HvfGicV3::new(~1.2 ms) and thediffoverlay (~75 ms at golden+3) are real but secondary. Lowering restore latency means attacking the eager full-RAM materialization, not the HVF-object or overlay stages.
Follow-up (lazy demand-paging), explored and shelved. The obvious lever — map guest RAM with no stage-2 access and demand-fault pages in on first touch (the read+write analog of the existing dirty-tracking write-fault path) — was prototyped and works correctly (single-vCPU and SMP, via a
DemandFaultexit on both data and instruction aborts). It was not kept, because the win could not be demonstrated:clonefile+mmap(MAP_SHARED)already demand-pages the base host-side, so a restore that touches only its working set may already pay only for the pages it uses. The numbers above are cache-state dependent — they reproduce when the basememory.binis not resident in the host page cache (e.g. after the dd phase evicts it); a tight-succession restore with a warm base measures ~1–7 ms. A definitive cold-base A/B (eager vs lazy, wall to first output) needssudo purgeto evict the cache reliably, which was unavailable in the test environment. The lever remains open if a cold-start workload shows the eager materialization is genuinely on the critical path.
4. Disk footprint
| Artifact | logical (st_size) | physical (st_blocks×512) |
|---|---|---|
Full memory.bin | 512.0 MiB (536,870,912 B) | 512.0 MiB |
Diff memory.bin (d1, 903 pages) | 14.79 MB | 14.79 MB |
Diff memory.bin (d2, 891 pages) | 14.60 MB | 14.60 MB |
Diff memory.bin (d3, 883 pages) | 14.47 MB | 14.47 MB |
A diff memory.bin is packed, not sparse — logical == physical == n_dirty × 16 KiB. Each ~8 MiB-dirtied diff is ~14.5 MB, ~35× smaller than the 512 MiB full
RAM image. (It’s >8 MiB because the guest dirties incidental pages — kernel,
shell, page cache — during the interval, not only the blob.)
Store totals. The golden + 3-diff chain’s total physical store was ~938 MB
(st_blocks×512 summed over all four layer dirs). That is dominated by each layer’s
disk.img, not by RAM: disk.img is written with APFS clonefile (copy-on-write),
so on disk the blocks are largely shared between layers even though each file’s
st_blocks counts them — the summed number overstates true consumption. The RAM side
is the honest delta: 4 full snapshots ≈ 4 × 512 MiB = 2048 MiB of memory images,
vs a golden + 3 diffs ≈ 512 + 3×~14.5 ≈ 556 MiB — a ~3.7× saving here, growing
with chain length and shrinking with per-diff dirty-set size.
Release-build data point
Same host, target/release/boot, to show the debug overhead. (Boot + restore only;
n=3, median.)
| Metric | Debug | Release |
|---|---|---|
Guest-boot-time untracked | 202 ms | 214 ms (211–237) |
Guest-boot-time tracked | 214 ms | 216 ms (211–218) |
| boot wall untracked | 1241 ms | 1259 ms (1255–1644) |
| boot wall tracked | 1256 ms | 1259 ms (1253–1261) |
| Restore-time (Full) | 245 ms | 243 ms (241–248) |
| restore wall (Full) | 257 ms | 257 ms (257–258) |
Release is not meaningfully faster here — every metric is within run-to-run
noise of the debug build. These timings are dominated by guest kernel/init work
and by host I/O / HVF (writing and reading the 512 MiB memory.bin, vCPU
exits), not by VMM CPU code the optimizer would speed up. So for these specific
boot/restore/snapshot-write metrics the debug-build caveat is largely moot. (A
CPU-bound VMM path — e.g. a huge diff pack or page scan — would still benefit from
--release; these workloads just aren’t CPU-bound in the VMM.)
Re-measured on AC power
The headline tables above were taken on battery, which can throttle the CPU.
To check whether that biased the numbers, the full suite was re-run with identical
parameters (--mem 512, n=3, same throwaway vmstore-bench/ store) on AC power
— pmset -g batt → “Now drawing from ‘AC Power’”, pmset -g therm → no thermal or
performance warning recorded. Same debug build, same host, same day.
Result: within noise of the battery run. Power source did not materially affect these metrics on this host. Side-by-side medians (n=3 each):
| Metric | Battery median | AC median | Δ | Δ % | Moved >10 %? |
|---|---|---|---|---|---|
Guest-boot-time untracked | 202 ms | 213 ms (208–224) | +11 ms | +5 % | no |
| boot wall untracked | 1241 ms | 1254 ms (1249–1608) | +13 ms | +1 % | no |
| dd 64 MiB untracked | 2100 MB/s | 2000 MB/s (2000–2100) | −100 MB/s | −5 % | no |
dd 64 MiB --track-dirty | 1500 MB/s | 1500 MB/s (1400–1700) | 0 | 0 % | no |
| Full snapshot write ‡ | 317 ms | 350 ms (327–359) | +33 ms | +10 % | borderline† |
| Diff write (8 MiB) ‡ | 339 ms | 339 ms (336–340) | 0 | 0 % | no |
| Diff write (64 MiB) ‡ | 372 ms | 388 ms (356–391) | +16 ms | +4 % | no |
| Restore Full (internal) | 245 ms | 239 ms (238–247) | −6 ms | −2 % | no |
| Restore Full (wall) | 257 ms | 257 ms (256–257) | 0 | 0 % | no |
| Restore golden+1 (internal) | 243 ms | 243 ms (241–245) | 0 | 0 % | no |
| Restore golden+3 (internal) | 242 ms | 244 ms (242–245) | +2 ms | +1 % | no |
Diff memory.bin (d1) | 14.79 MB | 14.88 MB (908 pages) | +0.09 MB | +1 % | no |
† The Full-write +10 % (317 → 350 ms) is at the noise floor, not in AC’s favor — AC was slower here, the opposite of a CPU-throttle story. The AC spread (327–359 ms) overlaps the battery band, so this is run-to-run jitter on the snapshot fixed-cost floor (quiesce + GIC + device serialize + RAM re-protect), not a power effect.
‡ Superseded. These three snapshot-write rows were measured with the old
console-poll harness, which timed Ctrl-A s keystroke → console line (300 ms drain
quantization + vCPU rendezvous + console latency), not the write. They are kept
only to show that even that conflated number was power-insensitive. The corrected
internal-timer write numbers are in §2 (Full 147 ms, Diff 17–58 ms) — those were
re-measured on battery; the write is bytes/I/O-bound, not CPU-clock-bound, so power
source is immaterial here too (same conclusion as every other row).
Tracked-boot was excluded from the table because both runs are dominated by a
cold-start outlier in the first --track-dirty boot (write-protect arming), and the
median lands on different samples run-to-run. Battery medians were 214 ms / 1256 ms
(steady samples ~211–214 / ~1254–1256, one 584 / 1624 outlier); AC’s steady samples
were ~230 ms / ~1274 ms with two slow 606–608 / 1645–1652 cold samples, so AC’s
median fell on the outlier (606 / 1645 ms). Comparing steady-state tracked
boots (AC ~230/1274 vs battery ~211–214/1254–1256) the gap is ≤20 ms — same noise
regime as the untracked column. This is a cold-cache/arming artifact, not throttling.
The two metrics most likely to move on AC — dd write throughput and the per-page fault tax — did not. dd untracked was if anything lower on AC (2000 vs 2100 MB/s, −5 %, inside the documented wide tmpfs spread), and tracked dd was identical at the median (1500 MB/s). The first-touch write-protect fault tax is a per-page guest/HVF cost, not a CPU-clock-bound one, so AC’s higher sustained clock buys nothing here. Boot and restore are guest- and I/O-bound and stayed flat as expected.
Net (power state): every metric reproduced within noise on AC — diff ~14.5–14.9 MB / ~35× smaller, ~12 ms tracked-boot tax (steady-state), ~28 % first-touch write-throughput tax (median; noisy band, reconfirmed), and ~240–245 ms flat restore across chain depth. The power source changed nothing material on this host.
Note on snapshot-write numbers. The write-time figures in this AC section (~317–388 ms) are from the superseded console-poll harness and are wrong as “write time” — see §2. The corrected internal-timer numbers are Full 147 ms / Diff 17–58 ms, and a Diff is meaningfully faster to write than a Full. Any article copy still saying “diffs aren’t faster to write (~340 vs ~317 ms)” must be revised.
Methodology & caveats
- Harness:
scripts/diff_snapshot_bench.py, drivingbootover a pty exactly asscripts/restore_test.py/scripts/diff_snapshot_test.pydo —\x01 sfor the snapshot escape, root login with no password, and paced (≤8-byte) keystroke bursts because the guest UART RX FIFO is only 16 bytes. Throwaway storevmstore-bench/(gitignored), removed at start and end. - Power state. Headline tables: battery. Full re-run on AC power (verified
via
pmset -g batt/pmset -g therm, no thermal/perf warnings) reproduced every metric within noise — see “Re-measured on AC power”. On this host the power source did not materially change boot, dd throughput, snapshot write, or restore. - Diff chains are built by restore-then-resnapshot. A single process cannot diff
against itself (one
write_nameper process + the same-name-as-parent guard), so each diff layer is produced by restoring its parent with--track-dirty --name <new>, dirtying ~8 MiB in/dev/shm, andCtrl-A s. This is the designed diff path. - Debug build. Unoptimized; a release build is faster (see table above). All other numbers are debug.
- Warm page cache, single vCPU, 512 MiB, minimal guest. Absolute numbers grow with RAM size and a fuller guest; the relative comparisons (Full vs Diff write, restore-by-depth, footprint) are the durable findings.
- dd-on-tmpfs is a noisy probe of the fault tax (see §1b) — reported as a median with a wide spread, not a clean constant.
- Clock domains differ.
Guest-boot-time/Restore-timeare stamped inside the VMM relative to VM start; the wall timers are hostspawn()→ console, including process-spawn overhead. They are complementary, not subtractable.
Reproduce
cargo build -p ignition-spike --bin boot && scripts/sign.sh target/debug/boot
python3 scripts/diff_snapshot_bench.py --mem 512 # full debug suite
python3 scripts/diff_snapshot_bench.py --release # release boot/restore point
Related
- Diff / incremental snapshots — the feature these numbers measure.
- The clone primitive — dirty tracking and the delta chain.
Snapshot-fuzzing benchmark
The in-VMM snapshot fuzzer resets the guest to a parse-entry snapshot every
iteration using hv_vm_protect dirty-page tracking, without leaving the VMM.
This page reports the M3 throughput and reset numbers for that machinery on real
hardware. For how the fuzzer works step by step, see
How snapshot fuzzing works.
Host: Apple Silicon (M3), macOS 26.5. Guest: aarch64, 128 MiB, single vCPU, 16 KiB page granule. Target: libpng 1.6.43 + zlib 1.3.1.
Results
| Metric | Value |
|---|---|
| Steady-state execs/sec (dirty reset) | 1309 |
| Steady-state execs/sec (full-copy reset) | 271 |
| Dirty vs full-copy speedup | 4.8x |
| Reset latency p50 / p99 | 36 / 60 us |
| page-copy p50 | 35 us |
| register-restore p50 | 1 us |
| Dirty-set size p50 / p99 / max (16 KiB pages) | 44 / 50 / 50 |
| Distinct edges (coverage) | 144 |
| Time-to-rediscover planted CVE (synthetic, ASan) | 0.002 s |
Dirty reset runs at 4.8x the throughput of a full-copy reset on the same target. The reset cost is dominated by the page copy (about 35 us); register restore is about 1 us. The dirty set the reset copies back is 44 to 50 pages per iteration. Coverage reached 144 distinct edges, and the planted heap-overflow CVE was rediscovered deterministically in 0.002 s from the seed corpus.
Methodology
- SanCov-only libpng build, no AddressSanitizer. The throughput, reset, and dirty-set numbers come from a coverage-only build so the snapshot machinery is isolated. ASan shadow (1/8 of the working set) would join the dirty set and inflate the reset, so the deterministic bug-finding number uses a separate ASan build.
- Single core, steady state. execs/sec is measured over a fixed wall-clock window after warm-up.
- The Linux/KVM cross-check was dropped from scope. These are ignition’s own dirty-reset vs full-copy numbers only.
Reproduce:
M3_DURATION=60 python3 scripts/fuzz_m3_bench.py
A browser you can throw away in 130 milliseconds
I built a disposable browser on Apple Silicon. Every session is a fresh Firefox running in its own microVM, cloned from a warm snapshot, networked, and discarded when you close the window. One keystroke resets it to a clean homepage.
What makes it fast is the snapshot. Cold-booting the VM and waiting for Firefox to paint its homepage takes about 7.8 seconds. Restoring an already-running, already-loaded Firefox from a snapshot takes 130 milliseconds. That is roughly 60x. The mechanism is an APFS clonefile plus a copy-on-write memory map, so restore does almost no work up front and pages fault in lazily as you browse.
The measurements, on an M-series Mac, 2 GiB guest, two cores:
- Cold boot to a painted homepage: 7774 ms (range 7618 to 8084 over three runs)
- Kernel plus early init alone: 599 ms (the rest of that 7.8 s is Firefox starting)
- Restore from snapshot to a running guest: 130 ms (range 127 to 131)
Two things stand out. The restore is flat: 127 to 131 ms regardless of what the browser was doing when the snapshot was taken, because nothing large is read up front. And almost all of the 130 ms is one specific cost. Breaking down a 132 ms restore: 93 ms is rebuilding the virtio device set (gpu, net, block, input), 39 ms is reattaching stdin, and everything else is under a millisecond. So if I ever want it faster, I know exactly where to look.
The disk never changes. The root filesystem is read-only, with a tmpfs overlay holding everything writable: profile, cache, downloads. All session state lives in RAM. Reset throws the RAM away and you are back to a clean machine. Nothing to scrub.
Getting a window on screen at all was its own piece of work. The microVM started life headless, just a serial console. Putting a real browser in front of someone meant the guest needed a display and a way to take input. That was two evenings.
The first evening was the display: a virtio-gpu device, 2D only, no Metal and no GL. The guest’s framebuffer renders into a host buffer, and the host blits that into a plain macOS window. Two commands carry the whole path, one to copy guest pixels out, one to present a frame. The second evening was input: two virtio-input devices, a keyboard and an absolute pointer, translating macOS key and mouse events into Linux evdev events and injecting them into the guest. After that the window could be typed into and clicked, the cursor tracked one to one, and cage could fullscreen Firefox inside it. Modest scope on purpose, and that is exactly why it landed in two sittings.
None of it is fast in the GPU sense. It is a software framebuffer. But for a browser you reset constantly, predictable beats clever, and a CPU blit you fully understand is easier to reason about than a render path you don’t.
Built on Hypervisor.framework, in Rust, sharing zero lines with Firecracker.
Where the pieces live
- Disposable browser — the overlay-root model,
building
rootfs-browser.ext4, the warm-base snapshot, fan-out, and the cold-reset (relaunch) hotkey. - GUI display — the virtio-gpu (2D) + virtio-input stack and the cage compositor behind the window.
- Snapshot & restore — the clonefile +
MAP_SHAREDrestore path these numbers measure. - Boot & restore latency — the full benchmark table the figures above come from.
HVF and Firecracker map
Status (2026-06): historical analysis — kept as the FC↔HVF reference. The KVM→HVF mapping (§3), run-loop/ESR decode (§4), threading inversion (§5), and interrupt-path (§6) remain accurate. But §1/§7’s premise that in-kernel
hv_gichas “no state get/set API” (opaque, lossy snapshots) is disproven —hv_gic_state_*gives lossless GIC save/restore (crates/hvf/src/gic.rs), so the userspace-GIC tradeoff did not arise. Phases 1–2 and HVF snapshot/restore have shipped; dirty-tracking/diff snapshots and the REST API remain open.
Derived from a side-by-side reading of containers/libkrun (HVF backend, originally a Firecracker
fork) and firecracker-microvm/firecracker (current main), June 2026. libkrun is Apache-2.0, same
license as Firecracker — its HVF code can be lifted nearly verbatim.
1. Size of the problem
| Component | libkrun (HVF/macOS) | Firecracker (KVM) | Notes |
|---|---|---|---|
| Hypervisor wrapper | src/hvf/src/lib.rs — 731 loc | kvm-ioctls/kvm-bindings crates (external) | + 4,712 loc bindgen output from Hypervisor.h (mechanical) |
| vCPU/VM state machine | src/vmm/src/macos/vstate.rs — 731 loc | src/vmm/src/vstate/{vcpu,vm,kvm}.rs + linux/vstate.rs equivalent ~2,055 loc | macOS side is smaller |
| GIC (in-kernel) | hvfgicv3.rs — 183 loc | arch/aarch64/gic/ — ~1,800 loc incl. full register save/restore | FC’s bulk is snapshot support |
| GIC (userspace fallback) | gicv3.rs + legacy/vcpu.rs ICC trap handling | n/a (KVM always in-kernel) | needed pre-macOS 15; possibly needed again for snapshots (§7) |
| Sysreg trap table | arch/src/aarch64/macos/sysreg.rs — 146 loc, 38 registers | n/a (KVM handles in-kernel) | |
| Arch boot/FDT | arch/src/aarch64/ — ~720 loc | arch/aarch64/{mod,fdt,regs,cache_info}.rs — ~2,580 loc | FC’s cache_info.rs (775 loc) parses Linux sysfs — no macOS equivalent, synthesize or omit |
| MMIO device manager | device_manager/hvf/mmio.rs — 569 loc | device_manager/mmio.rs (KVM-coupled via irqfd) |
Total hand-written macOS-specific code in libkrun: ~2,400 lines.
2. KVM coupling seam in Firecracker
Files using kvm_ioctls/kvm_bindings outside arch/{aarch64,x86_64} (the surface to abstract or fork):
src/vmm/src/vstate/kvm.rs — hypervisor handle → replace with HvfVm
src/vmm/src/vstate/vm.rs — VM + memory regions → hv_vm_create / hv_vm_map
src/vmm/src/vstate/vcpu.rs — vCPU threads + run loop → biggest rewrite (§3, §5)
src/vmm/src/vstate/memory.rs — GuestMemoryMmap + dirty log → mmap ports as-is; dirty log: no HVF API (§7)
src/vmm/src/vstate/interrupts.rs — irqfd → direct GIC injection (§6)
src/vmm/src/device_manager/mmio.rs — irqfd registration → sweep
src/vmm/src/device_manager/acpi.rs — x86 only → drop (aarch64-only port)
src/vmm/src/gdb/* — KVM debug regs → drop initially
Firecracker upstream tenets are explicitly KVM-only — plan for a permanently diverged fork.
3. API mapping: KVM → HVF
| KVM | HVF | Divergence |
|---|---|---|
KVM_CREATE_VM | hv_vm_create(config) | one VM per process on HVF |
KVM_SET_USER_MEMORY_REGION | hv_vm_map(uva, gpa, size, RWX) | near 1:1; hv_vm_unmap for ballooning |
KVM_CREATE_VCPU (fd, movable) | hv_vcpu_create (thread-bound) | must be called on the thread that runs it (§5) |
KVM_RUN → typed VcpuExit | hv_vcpu_run → raw hv_vcpu_exit_t (reason + ESR syndrome) | you decode ESR_EL2 yourself (§4) |
KVM_SET_ONE_REG | hv_vcpu_set_reg / hv_vcpu_set_sys_reg | different reg ID encodings (KVM u64 ids vs HVF enums) |
in-kernel GIC via KVM_CREATE_DEVICE | hv_gic_create(config) (macOS 15+) | no state get/set API (§7) |
irqfd (KVM_IRQFD) | none — hv_gic_set_spi(line, level) synchronous call | every device interrupt path changes (§6) |
| signal-based vCPU kick | hv_vcpu_request_exit → exit reason CANCELED | replaces FC’s KVM_KICK_SIGNAL machinery |
| in-kernel PSCI | none — you are the PSCI firmware | (§4.4) |
| WFI blocks in kernel | EC_WFX_TRAP exits to userspace | you implement the idle loop (§4.3) |
KVM_GET_DIRTY_LOG | nothing | dirty tracking via hv_vm_protect write faults — research item |
| vtimer handled in-kernel | HV_EXIT_REASON_VTIMER_ACTIVATED + hv_vcpu_set_vtimer_mask | manual mask/unmask sync each exit |
Bindings note: libkrun loads hv_gic_* via dlopen/libloading from
/System/Library/Frameworks/Hypervisor.framework so the binary still runs on macOS < 15.
Targeting macOS 15/26-only allows direct linking.
4. The run loop (libkrun hvf/src/lib.rs::run, the Rosetta stone)
HVF exit reasons: CANCELED (kicked), EXCEPTION (the real one), VTIMER_ACTIVATED.
For EXCEPTION, decode (syndrome >> 26) & 0x3f (EC field). libkrun handles exactly six classes:
4.1 EC_DATAABORT (0x24) → MMIO
Manual ISS decode: isv (bit 24), iswrite (bit 6), sas (bits 23:22, len = 1<<sas),
srt (bits 20:16, register number; 31 = xzr). Faulting GPA from exception.physical_address.
Deferred-read gotcha: HVF cannot complete the read in the handler. libkrun stashes
pending_mmio_read {addr, len, srt} plus pending_advance_pc = true, returns
VcpuExit::MmioRead(pa, &mut buf); the next run() entry writes the bus result into Xn
and advances PC by 4 before re-entering the guest. Writes are simpler: read Xsrt, hand bytes
to the bus, advance PC. KVM hides all of this.
4.2 EC_SYSTEMREGISTERTRAP (0x18)
Decode isread (bit 0), rt (bits 9:5), reg = syndrome & SYSREG_MASK (op0/op1/op2/CRn/CRm
packed — see macos/sysreg.rs encoding macro, 38 registers). Dispatch to
Vcpus::handle_sysreg_read/write — used by the userspace GIC for ICC_* registers
(ICC_IAR1_EL1, ICC_SGI1R_EL1 for SGIs/IPIs, ICC_EOIR1_EL1, priority regs), plus
debug regs (MDCCINT_EL1, OSLAR/OSDLR) as ignore-writes. With in-kernel hv_gic this
class nearly disappears.
4.3 EC_WFX_TRAP (0x1) — the userspace idle loop
Read CNTV_CTL_EL0: if timer disabled or masked → park indefinitely (WaitForEvent).
Else read CNTV_CVAL_EL0, compare against mach_absolute_time(); if already expired,
re-enter; else compute Duration from cntfrq and park with timeout
(WaitForEventTimeout). Parking = blocking on a per-vCPU crossbeam channel
(recv_timeout); device IRQ injection sends on the channel to wake. This is the vCPU
idle loop, in userspace.
4.4 EC_AA64_HVC (0x16) / EC_AA64_SMC (0x17) — you are PSCI
libkrun implements: PSCI_VERSION (→2), MIGRATE_INFO_TYPE (→2), SYSTEM_OFF/SYSTEM_RESET
(→ Shutdown), CPU_ON (read mpidr/entry/ctx from X1–X3, return 0 in X0, then the VMM sends
entry over a channel to the parked secondary vCPU thread, which only then calls
set_initial_state(entry, fdt) and starts running). SMC additionally needs manual PC advance;
HVC does not. SMCCC features beyond this minimal set (e.g. PSCI_FEATURES, CPU_SUSPEND)
will be probed by newer kernels — be ready to extend.
4.5 EC_AA64_BKPT (0x3c) — debugging hook.
4.6 VTIMER_ACTIVATED
Set vtimer IRQ (PPI) pending in the GIC, mark vtimer_masked = true; unmask via
hv_vcpu_set_vtimer_mask(false) once the guest EOIs (libkrun syncs in hvf_sync_vtimer
on each exit).
5. Threading model inversion
- KVM: vCPU fds created up front on the main thread, moved into worker threads, kicked via signals.
- HVF:
hv_vcpu_createinsideVcpu::run()after the thread spawns (thread-affine); kicked viahv_vcpu_request_exit(vcpuid). - libkrun MPIDR detail: vcpuid is written to Aff1 of
MPIDR_EL1at vCPU creation, otherwise redistributor IDs won’t match with in-kernelhv_gic. (Classic lost-week landmine.) - Boot regs are bit-identical to Firecracker: PC = kernel entry, X0 = FDT addr,
CPSR =
PSR_MODE_EL1h | A | F | I | D— samePSTATE_FAULT_BITS_64constant. The arm64 Linux boot protocol doesn’t care who the hypervisor is. FDT generation ports with plumbing changes only (dropcache_info.rssysfs parsing; GIC node fed fromhv_gic_get_{distributor,redistributor}_size- chosen base addresses; GICv3 maint IRQ = PPI 9, compatible = “arm,gic-v3”).
- Memory layout: libkrun aarch64 DRAM starts at the same 2 GB (
0x8000_0000) for kernel boot; GIC dist/redist placed just belowMMIO_MEM_START.
6. Device interrupt path (pervasive mechanical sweep)
Firecracker: device → EventFd → KVM irqfd → in-kernel injection. Fire and forget.
libkrun: device → IrqChip::set_irq(Some(line), _) → hv_gic_set_spi(line, true)
(+ wake any parked vCPU via its WFE channel / hv_vcpu_request_exit for running ones).
The EventFd parameter survives in the trait signature but is unused on the HVF path.
Every virtio device’s signal_used_queue path is touched. Also: no KVM_IOEVENTFD, so no
fast MMIO doorbells — every virtio kick is a full vmexit→userspace round trip (one of the
measurable perf deltas vs KVM Firecracker; worth benchmarking explicitly).
7. Snapshot/restore — the research-grade gap
Firecracker’s ~1,800 loc of gic/gicv3/regs/* exists solely to serialize GIC state
(dist/redist/ICC regs) via KVM_DEVICE_ATTR. The hv_gic_* API surface in libkrun’s bindings
has no state get/set — in-kernel HVF GIC state appears opaque. Consequences:
- vCPU core state: capturable (
hv_vcpu_get_reg/hv_vcpu_get_sys_regenumerating the register set — FC’sget_all_registerslogic maps over). - Guest memory: yours (mmap), trivially serializable. Dirty tracking: no
KVM_GET_DIRTY_LOGequivalent — implement viahv_vm_protectwrite-protect + fault-on-write logging. Genuinely novel work on this platform. - GIC state: either (a) use the userspace GICv3 (libkrun’s
gicv3.rslegacy path) where all state lives in your structs — snapshot trivially, pay sysreg-trap overhead; or (b) in-kernelhv_gicfor speed, accept lossy GIC snapshot (re-init + replay pending SPIs) — fine for many workloads, wrong in general; or (c) reverse whether newer macOS exposes GIC state APIs. This trade-off (perf vs snapshottability) is a paper section in itself. - vtimer offsets:
CNTVOFFhandling across save/restore needs care (HVF manages the offset; checkhv_vcpu_get/set_vtimer_offsetavailability).
8. Everything else that changes
- Event loop: FC’s
event-manageris epoll. Port to kqueue or shim withmio. Tedious, mechanical. - Block io_uring engine: drop; keep sync engine. Optional research-lite: kqueue/POSIX-AIO async engine.
- Net: no TAP on macOS. Options: unixgram/unixstream virtio-net backend to gvproxy/passt
(krunkit’s approach, incl. vfkit magic + offload negotiation), or vmnet (root or restricted
com.apple.vm.networkingentitlement). Keep FC’s virtio-net device, replace the TAP backend. - vsock: FC’s virtio-vsock is pure userspace over unix sockets — ports as-is.
- Jailer/seccomp: no Linux namespaces/seccomp. Initially stub; later: Seatbelt
(
sandbox_init) profile + separate uid. “Defense-in-depth for a Darwin VMM” is an open question. - Entitlements/signing:
com.apple.security.hypervisorentitlement; ad-hoc codesign suffices for local dev. - Nested virt (bonus): HVF on M3+/macOS 15+ exposes EL2. libkrun’s path: boot in
PSTATE_EL2h, setHCR_EL2/CNTHCTL_EL2, enable EL2+GICv3 bits inID_AA64PFR0_EL1, mask SME inID_AA64PFR1_EL1(guest hangs after MMU enable otherwise — another documented landmine). Enables KVM-inside-the-microVM on a Mac.
9. Suggested phases
- Boot-to-shell (weeks): lift
hvfcrate +hvfgicv3.rsfrom libkrun; newvstate/hvf_{vm,vcpu}.rsmirroringmacos/vstate.rs; virtio-blk (sync) + serial + vsock; kqueue event loop; FDT from FC’sfdt.rsminus cache_info. Single vCPU first — defer PSCI CPU_ON plumbing. - Parity-ish (month): SMP via CPU_ON channels; virtio-net over gvproxy; Firecracker REST machine-config API on top (the differentiator vs libkrun — existing firecracker-go-sdk tooling targets Macs unmodified); balloon via hv_vm_unmap.
- Research core (months): snapshot/restore — vCPU state enumeration, userspace-GIC
snapshot path, dirty tracking via
hv_vm_protect, diff snapshots; benchmark resume latency vs Linux/KVM Firecracker and boot/density vs Applecontainer(Virtualization.framework).
10. Files to read, in order
libkrun/src/hvf/src/lib.rs # the whole hypervisor abstraction, 731 loc
libkrun/src/vmm/src/macos/vstate.rs # thread model, WFE parking, run_emulation
libkrun/src/devices/src/legacy/hvfgicv3.rs # in-kernel GIC wrapper
libkrun/src/devices/src/legacy/vcpu.rs # VcpuList: IRQ bookkeeping + userspace ICC traps
libkrun/src/devices/src/legacy/gicv3.rs # userspace GIC (snapshot-friendly path)
libkrun/src/arch/src/aarch64/macos/sysreg.rs # ESR sysreg encoding
libkrun/src/vmm/src/device_manager/hvf/mmio.rs # MMIO bus without irqfd
--- vs ---
firecracker/src/vmm/src/vstate/{kvm,vm,vcpu}.rs # the seam to cut
firecracker/src/vmm/src/arch/aarch64/{vcpu,regs,fdt}.rs
firecracker/src/vmm/src/arch/aarch64/gic/ # what snapshotting demands of a GIC
Related
- Architecture — the same seam, described from the ignition side.
- Design decisions — why the VMM is shaped this way.
Design decisions
Status (2026-06): historical planning document — kept for lineage/rationale. Phases 1–2 have largely shipped (boot-to-shell, SMP, virtio-blk/net/rng/balloon/vsock, PL031 RTC, snapshot/restore including multi-vCPU and a lazy clonefile+mmap fast-restore). One premise below is disproven: in-kernel
hv_gicdoes expose lossless state get/set (hv_gic_state_*), so the GIC is snapshotted directly (crates/hvf/src/gic.rs) — the “userspace-GIC-for-snapshottability” tradeoff never materialized. Still open: the REST API and dirty-tracking/diff snapshots. See the validation spike for what was built.
This document transfers context from a planning conversation. Read it together with the HVF and Firecracker map (detailed file-by-file analysis) before starting work.
Goal
Research project: port AWS Firecracker (microVM VMM) to macOS on Apple Silicon, replacing KVM with Hypervisor.framework (HVF). Permanently diverged fork — Firecracker upstream is explicitly KVM-only by design tenet, so this needs its own name and repo.
Why it’s feasible — prior art
- libkrun (containers/libkrun, Apache-2.0, same license as Firecracker) is itself
derived from Firecracker’s codebase and already runs on HVF/macOS-ARM64. Its entire
macOS-specific layer is ~2,400 hand-written lines. It is the reference implementation
for this port; its
hvfcrate andhvfgicv3.rscan be lifted nearly verbatim. - krunkit (libkrun frontend) proves production viability, including GPU (Venus/Vulkan).
- Apple’s
container/containerization(Virtualization.framework, closed VMM) is the benchmark target, not a building block.
Where the novelty is (research contributions, in priority order)
- Snapshot/restore on HVF — nobody has this on macOS. Firecracker’s killer feature.
Two hard sub-problems:
- Dirty page tracking: no KVM_GET_DIRTY_LOG equivalent; implement via
hv_vm_protectwrite-protection + fault logging. - GIC state: in-kernel
hv_gichas NO state get/set API. Decision required: userspace GICv3 (libkrun’s legacy gicv3.rs — fully snapshottable, slower, every ICC_* access traps) vs in-kernel hv_gic (fast, opaque state, lossy snapshots). This perf-vs- snapshottability trade-off is itself a publishable analysis.
- Dirty page tracking: no KVM_GET_DIRTY_LOG equivalent; implement via
- Firecracker REST machine-config API on macOS — lets firecracker-go-sdk and existing orchestration target Macs unmodified. This is the differentiator vs just using libkrun.
- Benchmarks vs Apple container (Virtualization.framework) and vs Linux/KVM Firecracker: boot time, density, memory overhead, snapshot resume latency. Note: HVF has no KVM_IOEVENTFD, so every virtio kick is a full exit→userspace round trip — measure this delta explicitly.
Key technical findings from source reading (June 2026, both repos at main)
- KVM coupling seam in Firecracker:
src/vmm/src/vstate/{kvm,vm,vcpu,memory,interrupts}.rs,device_manager/mmio.rs, gdb target. That’s what gets replaced/forked. - HVF exit model: raw ESR_EL2 syndrome decoding in userspace. libkrun handles exactly 6 exception classes (DATAABORT→MMIO, SYSTEMREGISTERTRAP, WFX, HVC, SMC, BKPT).
- Gotchas already documented in the porting map:
- MMIO reads are deferred — complete register writeback + PC advance on NEXT run() entry.
- HVF vCPUs are thread-affine: hv_vcpu_create must run on the executing thread (inverts Firecracker’s create-then-move model; kick via hv_vcpu_request_exit, not signals).
- WFI/WFE traps to userspace — you implement the idle loop (park on channel with CNTV_CVAL-derived timeout against mach_absolute_time).
- You are the PSCI firmware (VERSION, SYSTEM_OFF/RESET, CPU_ON via channel to parked secondary vCPU threads; SMC needs manual PC advance, HVC doesn’t).
- MPIDR: write vcpuid to Aff1 or in-kernel GIC redistributor IDs won’t match.
- vtimer: manual mask/unmask sync per exit (hv_vcpu_set_vtimer_mask).
- Boot regs identical to KVM path: PC=entry, X0=FDT, CPSR=PSTATE_FAULT_BITS_64.
- No TAP on macOS: virtio-net over unixgram/unixstream to gvproxy/passt (krunkit pattern) or vmnet (needs root or restricted entitlement).
- vsock: Firecracker’s is pure userspace — ports as-is. io_uring block engine: drop, keep sync. event-manager is epoll: port to kqueue or shim with mio.
- Jailer/seccomp: no Linux equivalent; stub first, Seatbelt later.
- Nested virt available (M3+/macOS 15+): EL2 boot path exists in libkrun (HCR_EL2, CNTHCTL_EL2, ID_AA64PFR0_EL1 EL2+GIC3 bits, mask SME in ID_AA64PFR1_EL1 or guest hangs after MMU enable).
- Targeting macOS 15/26+ only is the sane choice (hv_gic_* APIs are macOS 15+; libkrun dlopens them for backward compat — direct linking is fine if we require 15+).
- Entitlement: com.apple.security.hypervisor; ad-hoc codesign suffices for local dev.
Phased plan
- Boot-to-shell (~weeks): lift libkrun’s hvf crate + hvfgicv3; new vstate/hvf_{vm,vcpu}.rs mirroring libkrun’s macos/vstate.rs; virtio-blk (sync) + serial + vsock; kqueue event loop; FDT from FC’s fdt.rs minus cache_info.rs (775 loc of Linux sysfs parsing — no macOS equivalent). Single vCPU first.
- Parity-ish (~month): SMP via PSCI CPU_ON channels; virtio-net via gvproxy; Firecracker REST API; balloon via hv_vm_unmap.
- Research core (~months): snapshot/restore + dirty tracking + GIC decision + benchmarks.
Concrete first task (validation spike)
Scaffold a minimal consumer of the lifted hvf crate that boots a kernel (from libkrunfw or Apple’s containerization kernel config) to a serial prompt on macOS 26 / Apple Silicon. Goal: confirm the lifted code compiles against the current macOS SDK headers before committing to fork structure.
Repos
- https://github.com/firecracker-microvm/firecracker (fork base)
- https://github.com/containers/libkrun (reference; lift src/hvf/, hvfgicv3.rs, macos/vstate.rs patterns; Apache-2.0)
- https://github.com/libkrun/krunkit (networking patterns: gvproxy unixgram, vfkit magic)
- https://github.com/apple/containerization (kernel config, benchmark target)
Reading order (paths verified)
libkrun/src/hvf/src/lib.rs # hypervisor abstraction, 731 loc
libkrun/src/vmm/src/macos/vstate.rs # threading, WFE parking, run_emulation
libkrun/src/devices/src/legacy/hvfgicv3.rs # in-kernel GIC wrapper, 183 loc
libkrun/src/devices/src/legacy/vcpu.rs # VcpuList: IRQ bookkeeping, ICC traps
libkrun/src/devices/src/legacy/gicv3.rs # userspace GIC (snapshot-friendly)
libkrun/src/arch/src/aarch64/macos/sysreg.rs # ESR sysreg encoding macros
libkrun/src/vmm/src/device_manager/hvf/mmio.rs # MMIO bus without irqfd
firecracker/src/vmm/src/vstate/{kvm,vm,vcpu}.rs # the seam to cut
firecracker/src/vmm/src/arch/aarch64/ # boot regs, FDT, GIC snapshot code
Environment notes for Claude Code
- Development machine must be Apple Silicon Mac, macOS 15+ (26 preferred).
- Rust toolchain, aarch64-apple-darwin target. bindgen for Hypervisor.h if regenerating bindings (or reuse libkrun’s checked-in bindings.rs, 4,712 loc).
- codesign with entitlements plist containing com.apple.security.hypervisor after every build, or hv_vm_create returns HV_DENIED.
- Guest kernel: libkrunfw bundles one; Apple containerization repo has an optimized config + containerized build env. Kata kernel config also works.
Validation spike
This chapter records the early end-to-end validation: from the first proof that
libkrun’s HVF code compiles and runs on the current macOS SDK, through the first
real Linux kernel boot, to the first interactive login prompt. The spike binary
(hvf-spike, later ignition-spike) has since been removed; its hvf-crate
coverage is subsumed by the boot binary and the crate tests, and the lifted code
now lives in the crates/ workspace. The results below are kept as the milestones
that de-risked the port.
The spike: lifted code compiles and runs
Date: 2026-06-12. Machine: Apple Silicon, macOS 26.5.1 (build 25F80), arm64. Toolchain: rustc/cargo 1.96.0 (Homebrew). SDK: MacOSX 26.5 (Xcode).
The concrete first task from the design decisions: confirm
libkrun’s hvf crate, lifted into a standalone consumer, compiles and runs against
the current macOS SDK before committing to fork structure.
The spike lifted, verbatim:
bindings.rs(4712 L) — libkrun’s generated Hypervisor.framework bindingslib.rs(731 L) →src/hvf/mod.rs— only edits: dropped#[macro_use] extern crate logforuse log::{...}, and repointed the one external deparch::aarch64::sysreg::{SYSREG_MASK, sys_reg_name}to a localcrate::arch.sysreg.rs(146 L) →src/arch.rs— copied unchanged.
Link: cargo:rustc-link-lib=framework=Hypervisor (same as libkrun’s vmm/build.rs).
Entitlement: ad-hoc codesign with com.apple.security.hypervisor.
The guest was 5 hand-assembled aarch64 instructions: store byte to unmapped MMIO
0x09000000 (→ EC_DATAABORT), then spin on WFI (→ EC_WFX_TRAP).
Results, all passing:
- Compiles: 0 errors, only dead-code warnings (unused enum variants/fields
the spike doesn’t exercise). Lifted code is clean against rustc 1.96 / edition
2024 (let-chains,
unsafe extern, etc. all fine). - Links + entitlement:
hv_vm_createsucceeds → framework linkage and the hypervisor entitlement both work with ad-hoc codesign. - Runs: VM + thread-affine vCPU created, 1 MiB guest RAM mapped, boot regs
set (PC, X0),
hv_vcpu_rundrove the guest. Observed exits, in order:MmioWrite(0x09000000, [0x48, 0, 0, 0])— ‘H’, correct addr/dataWaitForEvent— WFI decoded correctly
- Bindings ABI matches macOS 26.5 SDK (C probe vs checked-in asserts):
hv_vcpu_exit_tsize 32 / align 8,reason@0,exception@8;hv_vcpu_exit_exception_tsyndrome@0 / virtual_address@8 / physical_address@16;HV_EXIT_REASONCANCELED=0 / EXCEPTION=1 / VTIMER=2. Exact match.
Implications for the fork:
- libkrun’s checked-in
bindings.rsis reusable verbatim on macOS 26.5 — no bindgen regeneration needed. - The ESR_EL2 syndrome decode in
lib.rs::run()works as-is end to end. - Green light to commit to fork structure and proceed to Phase 1.
First real kernel boot
Date: 2026-06-12. Host: macOS 26.5.1, Apple Silicon.
Guest: Linux 6.1.0 aarch64 (Firecracker microvm-kernel-ci-aarch64-6.1.config),
built via kimage/build/build-kernel.sh. Booted with:
cargo build -p ignition-spike --bin boot
scripts/sign.sh target/debug/boot
target/debug/boot kimage/out/Image # 2>diag 1>guest-console
The success criterion was earlycon output. The kernel went much further: it booted
to the init/rootfs handoff (214 lines of console), then panicked only because no
root filesystem was provided (expected: no root=, no virtio-blk yet).
Harness diagnostics:
kernel : 16923136 bytes, entry=0x40000000
dtb : 1326 bytes @ 0x5fe00000
gic : dist=[0x3ffd0000, 0x10000] redist=[0x3ffe0000, 0x20000]
cmdline: console=ttyS0 earlycon=uart8250,mmio,0x9000000 reboot=k panic=1
Key proofs that every prior milestone composed correctly:
Machine model: linux,dummy-virt— the FDT root node.earlycon: uart8250 at MMIO 0x0000000009000000+ 200+ console lines — the 16550 serial over the MMIO bus anddefault_cmdline.NUMA: Faking a node at [mem 0x40000000-0x5fffffff]— the RAM layout.psci: PSCIv0.2 detected in firmware— the FDT psci node + HVC conduit; PSCISYSTEM_OFFat the end was handled by the run loop → clean exit.GICv3: 988 SPIs implemented,CPU0: found redistributor 0 region 0:0x3ffe0000— the in-kernelhv_gic, at exactly the redistributor addressHvfGicV3computed.arch_timer: cp15 timer(s) running at 24.00MHz (virt), clocksource +sched_clockregistered, BogoMIPS calibrated — the virtual timer worked; the run loop’s bounded WFI/WaitForEventTimeoutparking + vtimer masking was sufficient.
Final lines:
[ 0.046760] VFS: Cannot open root device "(null)" or unknown-block(0,0): error -6
[ 0.046965] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)
[ 0.048841] Rebooting in 1 seconds..
== guest requested shutdown (PSCI SYSTEM_OFF) -> [vcpu exited cleanly]
Findings: interrupt delivery to a login prompt
A real aarch64 Linux boots on ignition/HVF to an Alpine (none) login: prompt on
host stdout. The root cause that had been blocking it was the serial TX-empty
interrupt, a VMM-side fix, not the vtimer and not virtio, both of which were
already correct. Three theories preceded the right one; the evidence trail is kept
below so the dead ends aren’t re-walked.
The fix: the kernel’s interrupt-driven 8250 tty blocks after the 16-byte TX FIFO
fills, waiting for the THRE (TX-holding-register-empty) interrupt. Our 16550
(vm_superio::Serial) was wired with a no-op Trigger, so that interrupt was
never raised: OpenRC’s first service write filled the FIFO and hung, which looked
like a dead boot. printk’s console path polls THRE, so the kernel banner and
dmesg printed fine, masking the gap until userspace used the tty layer.
Wiring the serial’s Trigger to pulse the GIC’s serial SPI (INTID 32, the same
hv_gic_set_spi edge-pulse mechanism virtio already used) unblocked it. OpenRC
then ran every sysinit service to [ ok ], printed /etc/issue, and getty
emitted the login prompt.
crates/devices/src/serial.rs:SerialIrqenum{Noop, Gic(Arc<dyn IrqLine>)}implvm_superio::Trigger; theGicvariant asserts then deasserts the SPI (edge-rising; the GIC latches the edge).Serial::with_irq(out, irq)selects it;Serial::new(out)keeps theNoopline for the output-only smoke harnesses.spike/src/bin/boot.rs:GicIrq { gic, intid }now carries the absolute INTID; the serial is wired withintid = SERIAL_SPI + 32(= 32), virtio withVIRTIO_SPI + 32(= 33).
Reproduce: target/debug/boot kimage/out/Image kimage/out/rootfs.ext4 reaches
(none) login: (~236 console lines) in ~30 s. Re-sign after any rebuild;
cargo build --workspace relinks boot and strips the hypervisor entitlement
(hv_vm_create then fails with VmCreate); scripts/sign.sh target/debug/boot.
Evidence trail (theories disproven before the right one):
- vtimer delivery — WRONG.
HV_EXIT_REASON_VTIMER_ACTIVATEDnever fires; the in-kernelhv_gicdelivers the EL1 vtimer natively. The list-register injection experiment was moot and was reverted. - virtio completion-IRQ — WRONG. Logging every block request: 711 requests in
~31 s, all
status = 0, across distinct sectors — the guest acks every completion. virtio +hv_gic_set_spidelivery were already correct. - rootfs init / controlling-tty — WRONG. The boot looked gated on
OpenRC/getty config because output stopped mid-banner.
init=/sbin/gettythen printed exactly ~16 chars (Welcome to Alpin) before stopping — exactly the TX FIFO size — which finally fingered the serial TX interrupt as the real, VMM-side cause.
The ignition VMM boots a real aarch64 Linux to a userspace login prompt with a working virtio-blk rootfs, native virtual timer, and full interrupt delivery (virtio completion + serial TX). The shell-prompt bar is met; serial RX for interactive input followed on the next milestone.
Phase-1 follow-ups (historical)
Phase 1 is complete: a real aarch64 Linux boots on ignition/HVF to an interactive
root login over a bidirectional 16550 console, mounts an alpine rootfs via
virtio-blk, and runs SMP (--smp N, secondaries via PSCI CPU_ON). The items
below are the still-relevant leftovers and the hard-won reference facts.
Open / optional (no current bug; do when convenient)
hv_gic_config_tis leaked (crates/hvf/src/gic.rs) — a retained OS object, neveros_released, matchinghv_vm_config_t. Fine at process scope (one GIC for the process lifetime). Add aDropwrapper only if GICs ever become dynamic.text_offsetalignment (crates/arch/src/aarch64/kernel.rs) — a real-kernel validator could warn (not error) iftext_offset % 0x20_0000 != 0. Modern kernels are 2 MiB-aligned; the copy works regardless. Optional hardening.Bus::findis a linear scan (crates/devices/src/bus.rs) — fine at the current device count (serial + virtio). Revisit only if the device table grows large.- earlycon stride — the cmdline uses
earlycon=uart8250,mmio,0x9000000(byte stride). If a future kernel wants 32-bit register stride, switch touart8250,mmio32,...and widen theSerialaccess gate (currently 1-byte). Not a bug — a configuration contingency.
Deferred by design
GicInfosingle redistributor region — moot for HVF. Multiple#redistributor-regionsonly matter for discontiguous redistributors. Apple’shv_gicalways lays out ONE contiguous region (per_cpu_size × vcpu_countfrom a singleredist_base; seeHvfGicV3::new), so the single-regionGicInfo+create_gic_nodeis correct for any vCPU count here. Revisit only if a future host produces split redistributor regions.- CPU hotplug (
CPU_OFF, sysfs online/offline) — out of scope. SMP models bring-up only; an unknown PSCI call (incl.CPU_OFF) returnsNOT_SUPPORTEDrather than acting.
Standing constraints (not bugs)
Serial/BusDevicehandle 1-byte accesses only (data.len() == 1); other widths are logged and dropped. Correct for a 16550 (byte-wide registers) and the guest (strb/ldrb). A driver doing wider register access would silently no-op. Intentional, logged.NoIrqVcpusstubs the userspace interrupt/sysreg path (handle_sysreg_read=>Some(0),handle_sysreg_write=>true, no userspace IRQ injection). This is the correct permanent impl for this design: the in-kernelhv_gicdelivers all interrupts and per-cpu timers natively, so the userspaceVcpuspath is intentionally inert, not a stopgap. Lives once inhvf::NoIrqVcpus, shared by both vCPU runners.
Reference facts (HVF / Apple Silicon, macOS 26)
These were verified during bring-up and remain true; useful when extending the VMM.
GIC:
hv_gic_set_spitakes the ABSOLUTE GIC INTID (SPI =32 + spi_index). The 16550 wiresSERIAL_SPI(0) + 32 = INTID 32; virtioVIRTIO_SPI(1) + 32 = 33.- Create order:
hv_vm_create→HvfGicV3::new(before any vCPU). The GIC must exist before vCPU threads spawn. - HVF-reported sizes: distributor
0x10000, redistributor0x20000per vCPU.HvfGicV3::new(1, 0x4000_0000)placed dist=0x3ffd0000, redist=0x3ffe0000— valid IPAs below the MMIO window.gic_topis the address the GIC sits just below (guest RAM base).
Boot debug checklist (target/debug/boot [--smp N] <Image> [rootfs]):
Diagnostics on stderr, guest console on stdout (2>diag.txt to separate). Expected
banner: entry=0x40000000 for a modern defconfig kernel (text_offset=0, loaded at
the 2 MiB-aligned RAM_BASE). Re-sign after every build
(scripts/sign.sh target/debug/boot); cargo build strips the entitlement and
hv_vm_create then fails VmCreate.
Symptom → cause:
- No output at all → DTB/cmdline mismatch or wrong load addr. Check the banner’s
entry/fdt addrs; confirm the kernel has 8250/16550 earlycon
(
CONFIG_SERIAL_8250_*) and theuart@9000000nodecompatible="ns16550a". - Boots but no shell prompt → rootfs init/getty issue, not the VMM: the console is bidirectional and the serial TX/RX interrupts work.
- A secondary CPU never comes online under
--smp N→ check stderr forCPU_ON for ... ignored(MPIDR mismatch) and confirm the guest kernel hasCONFIG_SMP+ PSCI. The FDT advertisespsci method="hvc"and N cpu nodes.
Kernel loader:
arch::aarch64::kernel::load_kernel(ram, RAM_BASE, &image)returns the entry address;arch::aarch64::layout::fdt_addr(ram_size)gives the DTB address. Write the DTB into the host RAM slice atfdt_addr - RAM_BASE.image_size > file size(BSS):load_kernelcopies onlyimage.len()bytes; the delta is satisfied by pre-zeroed guest RAM. Correct — do not “fix” it to copyimage_sizebytes.
Specs & plans (agentic reference)
The design specs and implementation plans live under docs/superpowers/ and are
kept in place rather than folded into this book. They are the format the
subagent-driven workflow consumes directly: docs/superpowers/specs/ holds the
design specs (what to build and why), and docs/superpowers/plans/ holds the
implementation plans (the step-by-step instructions a subagent executes). Keeping
them in their native layout means an agent can read them as-is, so they remain the
canonical agentic reference.
Examples
Runnable walkthroughs live under the top-level examples/ directory.
- Diff-snapshot fan-out — one warm base, many cheap forks.
- Snapshot-fuzzing demo — a runnable fork-server twin of the in-VMM fuzz loop.
- vsock round-trip — both directions (guest→host E1, host→guest E2) with
socaton each end.